使用python实现时间处理代码
现有一个(n×2)的df1(df1内一列是时间,但不连续),本人想新建一个(m×2)的df2,df2的第一列添加指定时间开头和结尾(df1内的时间开头和结尾),此按秒递增,同时第二列的内容为将df1与df2相同时间的内容赋与df2,不同的赋NaN。
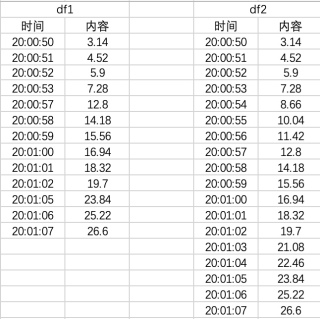
根据你问题的描述设计了相关的表格,表格名为data,内容如下:
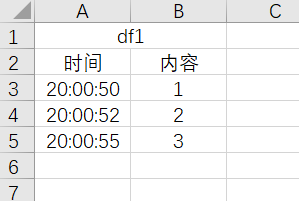
相应的代码为:
import pandas as pd
path1 = r'C:\Users\Desktop\data.xlsx'
df1 = pd.read_excel(path1, header=1)
df1["时间"] = df1["时间"].astype("str")
start = df1["时间"][0]
end = df1["时间"][(len(df1) - 1)]
time = pd.date_range(start=start, end=end, freq='S')
str1 = time.strftime("%Y-%m-%d %H:%M:%S").to_list()
time2 = [x.split(' ')[1] for x in str1]
df2 = pd.DataFrame({'时间': time2})
df3 = pd.merge(df1, df2, on='时间', how="right")
print(df3)
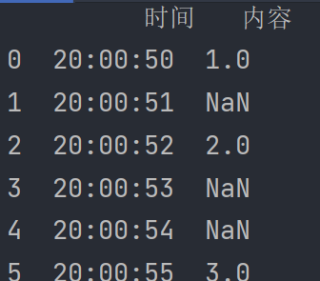
运算的结果为:
如果问题得到解决的话请点 采纳~~~
可以使用pandas中的merge函数来实现。
首先,新建df2,设置时间列的起始时间和终止时间,并使用pd.date_range函数将时间列的起始时间和终止时间按秒递增。
然后,使用merge函数将df1与df2合并,设置on参数为时间列,设置how参数为'outer',即取df1和df2的并集。
最后,使用df2.fillna函数将df2中的NaN值填充为想要的内容。
简单写了些代码:
import pandas as pd
//新建df2,设置时间列的起始时间和终止时间
df2 = pd.DataFrame({'time': pd.date_range(start='2020-01-01', end='2020-01-03', freq='S')})
//使用merge函数将df1与df2合并,
//取df1和df2的并集
df = pd.merge(df1, df2, on='time', how='outer')
//使用df2.fillna函数将df2中的NaN值填充为想要的内容
df2 = df2.fillna(0)
from datetime import datetime, timedelta
import pandas as pd
# 创建 df1
df1 = pd.DataFrame({'时间': ['20:00:50', '20:00:51', '20:00:52', '20:00:53', '20:00:57', '20:00:58', '20:00:59', '20:01:00', '20:01:01', '20:01:02', '20:01:05', '20:01:06', '20:01:07'],
'内容': [3.14, 4.52, 5.9, 7.28, 12.8, 14.18, 15.56, 16.94, 18.32, 19.7, 23.84, 25.22, 26.6]})
# 将 df1 中的时间字符串转换为时间对象
df1['时间'] = df1['时间'].apply(lambda x: datetime.strptime(x, '%H:%M:%S'))
# 获取 df1 中的最小时间和最大时间
min_time = df1['时间'].min()
max_time = df1['时间'].max()
# 创建时间列表
time_list = []
time = min_time
while time <= max_time:
time_list.append(time)
time += timedelta(seconds=1)
# 使用时间列表创建新的 DataFrame
df2 = pd.DataFrame({'时间': time_list})
# 合并 df1 和 df2
df = df2.merge(df1, on='时间', how='left')
# 重命名 DataFrame 的列名
df = df.rename(columns={'时间': '时间', '内容_y': '内容'})
print(df)
望采纳。
- 可以查看手册:python- 日期和时间 中的内容