同样的代码使用openmp在不同的程序中,加速效果差距
我使用openmp对一段代码进行并行加速,使用了32个线程,在下面代码里面测试加速了8-9倍,而把它加入到别的程序里面只有0.5倍的加速,而且还不稳定,有时候没效果。
#include <stdio.h>
#include <mpi.h>
#include <iostream>
#include <stdlib.h>
using namespace std;
#ifdef _OPENMP
#include <omp.h>
#endif
#define NXT 256
#define NYT 128
#define NZT 128
#include <sys/time.h>
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp, NULL);
return (double)tp.tv_sec + (double)tp.tv_usec * 1.e-6;
}
int main()
{
MPI_Init(NULL, NULL);
double *p, *u, *v, *w;
p = (double *)malloc((NXT + 2) * (NYT + 2) * (NZT + 2) * sizeof(double));
u = (double *)malloc((NXT + 2) * (NYT + 2) * (NZT + 2) * sizeof(double));
v = (double *)malloc((NXT + 2) * (NYT + 2) * (NZT + 2) * sizeof(double));
w = (double *)malloc((NXT + 2) * (NYT + 2) * (NZT + 2) * sizeof(double));
double t1, t2;
t1 = cpuSecond();
for (int n = 0; n < NXT*NYT*NZT; ++n)
{
int i = n / (NYT * NZT) + 1;
int j = (n % (NYT * NZT)) / NZT + 1;
int k = (n % (NYT * NZT)) % NZT + 1;
int id = i * (NYT + 2) * (NZT + 2) + j * (NZT + 2) + k;
u[id] = 1;
v[id] = 1;
w[id] = 1;
p[id] = 1;
}
t2 = cpuSecond();
cout << " noomp:" << t2 - t1 << endl;
t1 = cpuSecond();
#pragma omp parallel for
for (int n = 0; n < NXT*NYT*NZT; ++n)
{
int i = n / (NYT * NZT) + 1;
int j = (n % (NYT * NZT)) / NZT + 1;
int k = (n % (NYT * NZT)) % NZT + 1;
int id = i * (NYT + 2) * (NZT + 2) + j * (NZT + 2) + k;
u[id] = 1;
v[id] = 1;
w[id] = 1;
p[id] = 1;
}
t2 = cpuSecond();
cout << " omp:" << t2 - t1 << endl;
MPI_Finalize();
return 0;
}
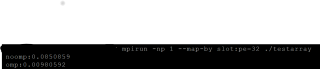
下面是这个程序加速效果,另一个程序比较大,但是加速的代码段,数据规模都是一样大的。
无profiler不要谈效率!!尤其在这个云计算、虚拟机、模拟器、CUDA、多核 、多级cache、指令流水线、多种存储介质、……满天飞的时代!
是否用了嵌套并行?