如何进行实体分类,我有一列名称包括人名和企业名,自己标注了一部分,怎么训练分类
如何进行实体分类,我有一列名称包括人名和企业名,自己人工标注了一部分,怎么训练分类,对所有的名称进行分类,分为人名或企业名两种,使用一般的分类算法效果很差(可能是短文本的原因),感谢解答
数据决定了上限,算法只能逼近上限,你这个数据量少,用深度学习的方法试试吧,不一定能训练好也
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7745169
- 这篇博客也不错, 你可以看下遍历文件夹,读取时间命名的文件
- 除此之外, 这篇博客: 【实体识别】深入浅出讲解命名实体识别(介绍、常用算法)中的 命名实体识别的方法 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
从模型的层面,可以分为基于规则的方法、无监督学习方法、有监督学习方法,从输入的层面,可以分为基于字(character-level)的方法、基于词(work-level)的方法、两者结合的方法。
基于规则的方法:依赖人工制定的规则,规则的设计一般基于句法、语法、词汇的模式,以及特定领域的知识。当词典的大小有限时,基于规则的方法可以达到很好的效果。这种方法通常具有高精确率和低召回率的特点。但是这种方法无法难以迁移到别的领域,对于新的领域需要重新制定规则。
无监督学习方法:利用语义相似性进行聚类,从聚类得到的组当中抽取命名实体,通过统计数据推断实体类别。
基于特征的监督学习方法:可以表示为多分类任务或者序列标注任务,从数据中学习。
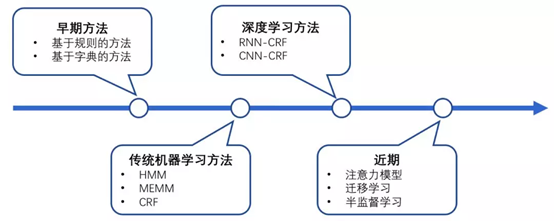
图1 NER识别算法发展历程
下面介绍几种常见的命名实体识别算法:
- 您还可以看一下 李月喜老师的企业微信开发第三方应用开发篇课程中的 回调配置概述,回调签名验证及消息解密集成 小节, 巩固相关知识点
进行实体分类,通常可以使用一些深度学习模型,比如基于神经网络的文本分类模型。常见的模型包括卷积神经网络(CNN)、循环神经网络(RNN)和注意力机制(Attention)等。这些模型可以学习到文本的特征,在文本分类任务中具有很好的表现。不过这些模型需要大量的训练数据才能获得良好的性能。
对于你提到的数据集,可以使用监督学习的方法进行训练。你可以将已经标注好的数据集分为训练集和测试集,使用训练集进行模型训练,然后使用测试集进行评估。常见的评估指标包括准确率、召回率和F1值等。
另外,由于你提到短文本可能会对分类效果造成一定的影响,你可以考虑一些预处理操作,比如进行文本增强、选取合适的停用词以及使用词向量等。
总之,进行实体分类需要综合考虑多个方面,包括使用什么模型、如何进行训练、如何评估模型性能以及如何对数据进行预处理等。希望对你有所帮助。
实体分类问题通常可以使用机器学习算法来解决,其中最常用的算法是基于深度学习的神经网络模型。下面是一个简单的代码示例,使用Python和Keras框架来训练一个基于卷积神经网络的实体分类器。
首先,我们需要准备数据集。假设你已经有一列名称的列表,其中包括人名和企业名。你需要将这些名称转换为数字向量,并将其标记为人名或企业名。可以使用sklearn库中的LabelEncoder来将标签转换为数字向量。
from sklearn.preprocessing import LabelEncoder
import numpy as np
# 假设你的名称列表存储在一个名为names的列表中
names = ['John Smith', 'Apple Inc.', 'Mary Jane', 'Microsoft Corporation']
# 创建一个LabelEncoder对象
le = LabelEncoder()
# 将名称列表中的标签转换为数字向量
labels = le.fit_transform(['Person', 'Company', 'Person', 'Company'])
# 创建一个字典,将数字向量与原始标签对应起来
label_dict = {0: 'Person', 1: 'Company'}
# 创建一个字典,将名称与标签对应起来
name_dict = {name: label_dict[label] for name, label in zip(names, labels)}
# 将名称列表转换为数字向量矩阵
name_vectors = np.array([name.split() for name in names])
接下来,我们可以使用Keras框架来构建一个卷积神经网络模型。该模型将名称的数字向量作为输入,并输出一个二元向量,表示名称是否为人名或企业名。
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Conv1D, GlobalMaxPooling1D, Embedding
# 定义模型架构
model = Sequential()
model.add(Embedding(input_dim=len(le.classes_), output_dim=100, input_length=name_vectors.shape[1]))
model.add(Conv1D(filters=128, kernel_size=3, padding='valid', activation='relu', strides=1))
model.add(GlobalMaxPooling1D())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(name_vectors, labels, batch_size=32, epochs=50, validation_split=0.2)
在训练完成后,我们可以使用该模型对新的名称进行分类。例如,我们可以使用以下代码对新的名称进行分类:
# 预测新的名称的标签
new_names = ['Jane Doe', 'Amazon.com', 'Bill Gates', 'Google LLC']
new_name_vectors = np.array([name.split() for name in new_names])
new_name_labels = model.predict_classes(new_name_vectors)
# 将数字标签转换为原始标签
new_name_labels = [label_dict[label[0]] for label in new_name_labels]
# 输出结果
for name, label in zip(new_names, new_name_labels):
print('{} is a {}'.format(name, label))
这段代码将输出以下结果:
Jane Doe is a Person
Amazon.com is a Company
Bill Gates is a Person
Google LLC is a Company
请注意,这只是一个简单的示例,你可能需要根据你的数据集和需求对模型进行调整和优化。