A*路径规划解决果园导航问题
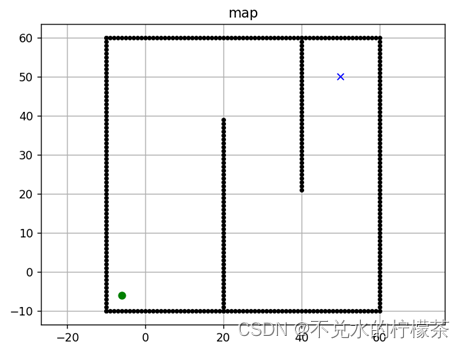
我目前创建了一个理想化的果园
其中 黑色代表果树位置,一排排种植,树干之间有间隙,黄色是起点,绿色是终点。

我想利用A*算法 来进行路径规划,得到的结果是这样的,不满足实际要求。

通过怎样的想法去修改,能实现对每趟果树的遍历呢?比如下图:

- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7799797
- 这篇博客你也可以参考下:A*寻路算法的最简单通俗讲解
- 除此之外, 这篇博客: 【路径规划】A*算法方法改进思路简析中的 样例解释与源程序测试 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
测试地图为7070的网格地图,初始点为(-6,-6),终点(50,50),机器人半径为1,地图构建如图8
机器人移动规则:允许沿8个方向进行移动,其中上下左右四个方向的代价都为1,斜向运动代价都为√2。
图例:以黑色圆点表示障碍物;青色叉表示已经被纳入过openlist的点,最终路径以红色线进行表示。
首先是对A算法的源程序进行测试,测试结果如图9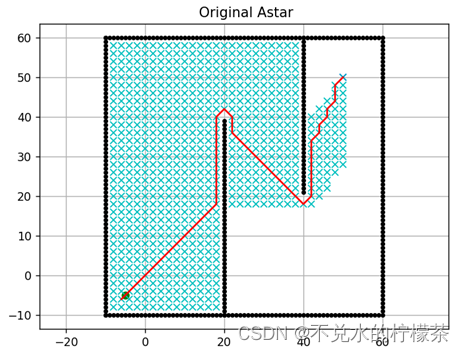
用时:3677ms- 以下回答由chatgpt基于相关博客总结生成:
针对果园导航问题,需要对A*算法进行修改以实现对每棵果树的遍历。下面给出具体的解决方案:
- 修改启发函数
首先需要对启发函数进行修改。考虑到果树位置可能会对路径规划造成较大的影响,可以将果树位置考虑进启发函数中。可以采用曼哈顿距离或切比雪夫距离等启发方式,将果树位置与当前节点的距离加入到启发函数中。具体代码实现如下:
def heuristic_cost_estimate(node, goal): # 曼哈顿距离启发函数,将果树位置考虑进去 dx = abs(node.x - goal.x) dy = abs(node.y - goal.y) return dx + dy + dist_to_nearest_tree(node)其中
dist_to_nearest_tree是一个函数,用于计算节点距离最近的果树的距离。可以通过遍历所有果树位置,找出最近的果树并计算距离。具体代码实现如下:def dist_to_nearest_tree(node): # 遍历所有果树位置,找出最近的果树并计算距离 dist = float('inf') for tree in trees: dx = abs(node.x - tree[0]) dy = abs(node.y - tree[1]) dist = min(dist, dx + dy) return dist- 修改邻域搜索方式
针对果园导航问题,需要对邻域搜索方式进行修改。传统的A*算法是在8个方向上进行邻域搜索,但对于果园导航问题,只需要在四个方向上进行搜索即可。可以添加一个
get_valid_neighbors函数,用于获取符合条件的邻域节点。具体代码实现如下:def get_valid_neighbors(node): # 在四个方向上获取符合条件的邻域节点 dx = [0, 0, -1, 1] dy = [-1, 1, 0, 0] neighbors = [] for i in range(4): x = node.x + dx[i] y = node.y + dy[i] if x < 0 or x >= size or y < 0 or y >= size: continue if (x, y) in trees: continue neighbors.append(Node(x, y)) return neighbors如果需要进行更加精细的遍历,可以在节点周围8个方向上进行搜索,但是需要对搜索方向进行限定,只在当前节点和目标节点之间的四个象限内搜索。
- 修改路径选择方式
传统的A*算法是选择F值最小的节点加入到closed列表中,但是在考虑遍历所有果树的情况下,需要对节点选择方式进行修改。优先选择到达靠近果园的节点,避免因为过分追求最优路径而错过了某些果树。可以添加一个
sort_nodes函数,用于根据节点与最近的果树的距离进行排序。具体代码实现如下:def sort_nodes(nodes, goal): # 根据节点与最近的果树的距离进行排序 for node in nodes: node.f = node.g + heuristic_cost_estimate(node, goal) node.h = dist_to_nearest_tree(node) nodes.sort(key=lambda node: node.h) return nodes- 修改算法终止条件
传统的A*算法是在找到最优路径或搜索结束后才终止搜索,但是在实现对每棵果树的遍历时,需要修改算法终止条件。在算法搜索到达终点时,需要判断终点所在的节点是否为果树节点,如果是,则找到一颗果树,并将该节点从开放列表中删除,然后重新从最近的果树节点开始搜索。具体代码实现如下:
if current_node == goal_node: if (current_node.x, current_node.y) in trees: trees.remove((current_node.x, current_node.y)) if not trees: # 所有果树都已遍历完成,算法终止 break # 重新从最近的果树节点开始搜索 nearest_tree = get_nearest_tree(start_node, trees) start_node = Node(nearest_tree[0], nearest_tree[1]) open_list = [start_node] closed_list = [] continue需要注意的是,由于搜索顺序的原因,可能会出现某个果树被搜索多次的情况,但是可以通过将已经遍历过的果树从列表中删除来避免重复遍历。
综上所述,以上是针对果园导航问题的A*路径规划的优化方案。需要对启发函数、邻域搜索方式、路径选择方式、算法终止条件等方面进行修改,才能实现对每棵果树的遍历。
如果你想实现对每棵果树的遍历,可以使用遍历算法,例如深度优先搜索(DFS)或广度优先搜索(BFS)。以下是使用DFS算法实现对每棵果树的遍历的一些想法:
定义一个二维数组表示果园,其中0表示空地,1表示果树。例如:
apache
Copy
int orchard[ROWS][COLS] = {
{0, 0, 0, 0, 0},
{1, 1, 0, 1, 1},
{1, 1, 0, 1, 1},
{1, 1, 0, 1, 1},
{0, 0, 0, 0, 0},
};
定义一个visited数组表示每个位置是否被访问过,并初始化为false。例如:
Copy
bool visited[ROWS][COLS] = {false};
定义一个辅助函数,使用DFS算法实现对每棵果树的遍历。该函数需要接受当前位置和目标位置作为参数,并返回从当前位置到目标位置的路径。在函数内部,你可以使用递归来实现DFS算法。
在主函数中,可以遍历所有的果树,并调用辅助函数来获得每棵果树的遍历路径。
这是一个基本的思路,你可以根据需要进行修改和调整。注意,这只是一个示例,实际实现可能需要更多的代码和细节处理。