YOLOv5运行报错,如何解决?
已经训练模型跑了200轮,但是打算修改参数重新训练的时候出现了以下报错


1.确认下你的环境是不是外部修改了,比如conda之类的虚拟环境被你重新命名了,删除了之类的。如果你用的是conda的话,请在终端或者命令行中输入以下命令确认下环境是否存在和变动(pychram的终端前面要是显示的是ps的话,要先输入cmd回车在输入)
conda info -e

2.pycahrm里面python编译器被你换掉了,这点在设置的项目管理这里确认下

- 重启大法,有时候你看着停下来了,但是后台程序还在占用其中某些部分,也可能导致这个问题(但是一般不会出现未定义模块的问题,所以这点有点存疑,估计效果不大,可以死马当活马医试下)
- 有可能你的硬盘啥的坏了导致你的环境真的出问题了,运气不好就只能重新安装了。
把环境删掉之后,重新在conda下搭建一个虚拟环境跑一下吧,感觉多半是环境问题
以下是可能导致“YOLOv5运行报错”的一些常见原因和解决方案:
参数设置错误:修改参数时,有时候会出现参数设置错误的情况,例如输入的参数类型不正确、参数值范围超过了系统限制、或者一些参数与其他参数冲突等。解决此问题的方法包括检查输入的参数是否正确,阅读文档并遵循建议的配置。
确认模型路径:重新训练时,可能需要重新编写代码指定新的模型路径。请确保新指定的模型路径存在,并且代码中该路径是否正确
模型版本不兼容:如果你完成修改后,在执行模型训练的时候,发现代码调用的YoloV5版本与你当前运行的环境不相同,可能会导致出现不兼容的情况。解决此问题的方法包括升级环境或使用相应的版本API或库件。
依赖项错误:如果程序无法找到所需的库,请确保所需的包已经安装并启用。检查您的Python虚拟环境,确保您正确地安装了所有必需的依赖项。
如果以上解决方案都无法解决问题,请提供更详细的错误信息和您正在使用的YOLOv5版本,以便我们更好地帮助您解决问题。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7643855
- 这篇博客也不错, 你可以看下从零开始完成Yolov5目标识别(一)准备工作
- 除此之外, 这篇博客: YOLOV5 参数设定与模型训练的坑点一二三中的 重新训练 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
来看看咱们原来的指令
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/mydata.yaml --epoch 200 --batch-size 4 --device 0首先第一个呢,其实迁移学习的意思,用训练好的参数去再训练,而不是默认值,这样会快一点
第二个参数呢,是那个模型的参数设置,分几个类呀啥的
第三个参数,指定咱们的数据集
第四个参数,训练次数(时长,这样理解)
第五个参数,一次性进入训练的数据集大小(个数)
第六个参数,训练平台(我这里是cuda0也就是用我自己的显卡训练GTX1650(害,穷,垃圾卡先用着))所以现在,我们训练的轮数可能太少了,所以嘞,我们就用300看看(默认也是300)
现在这里的话为了方便,我就直接在文件里面改了
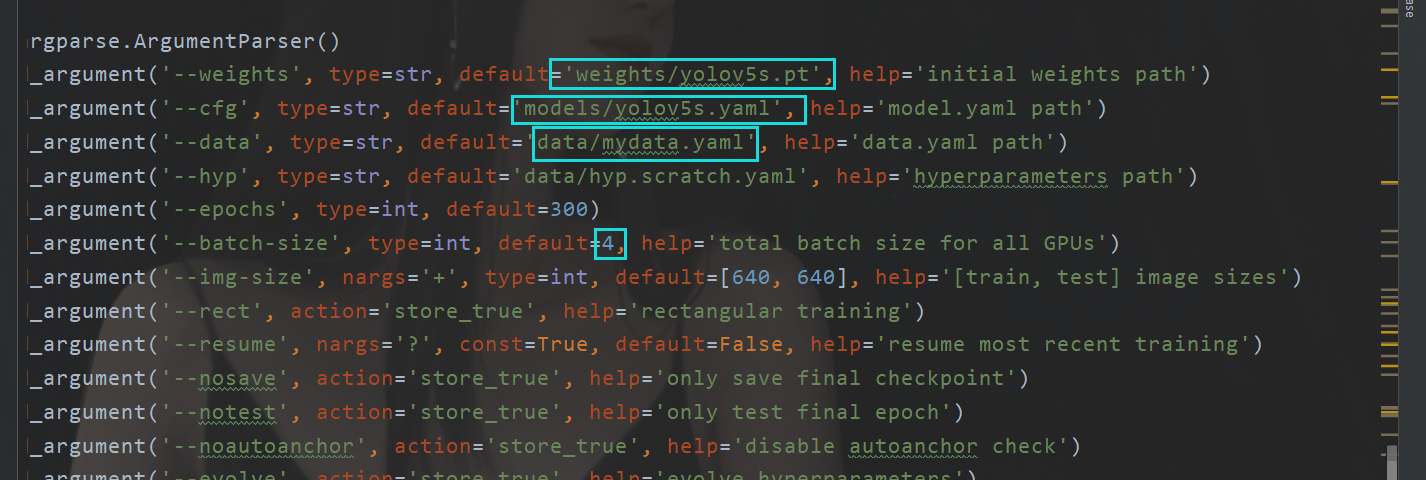
直接让它运行,之后咱们来查看结果
tensorboard --logdir=runs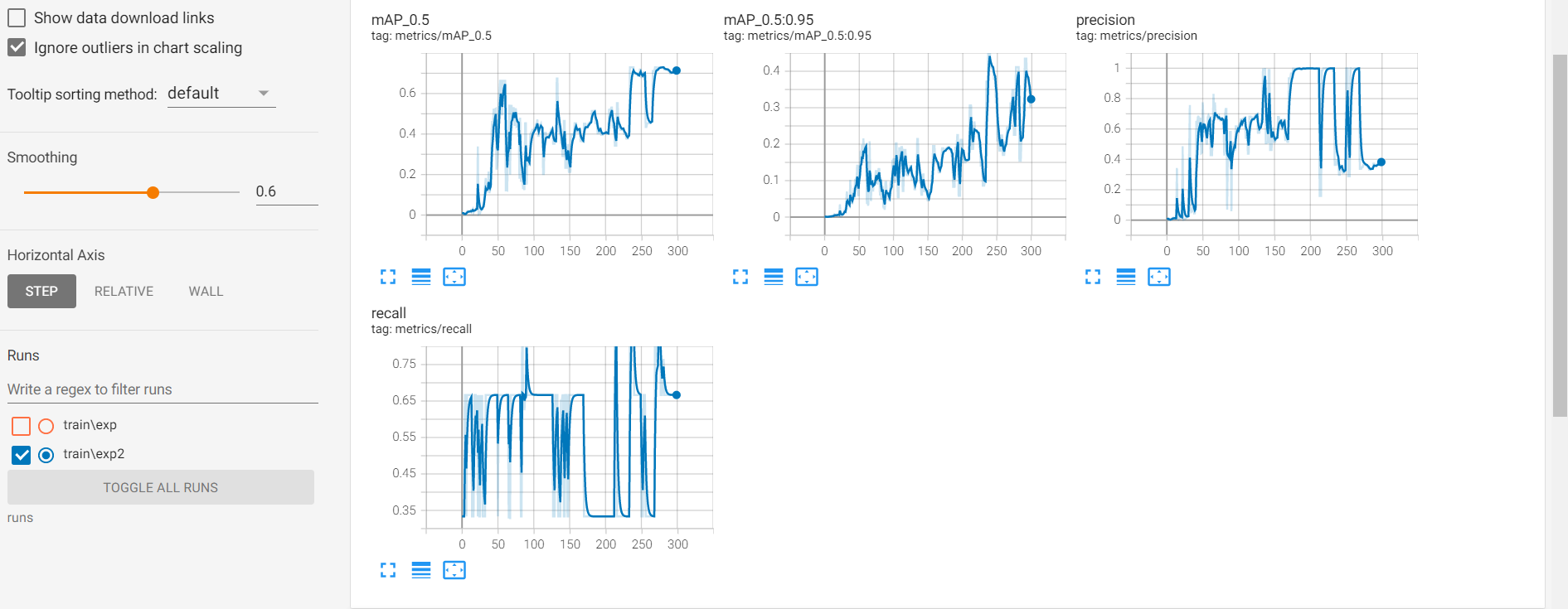
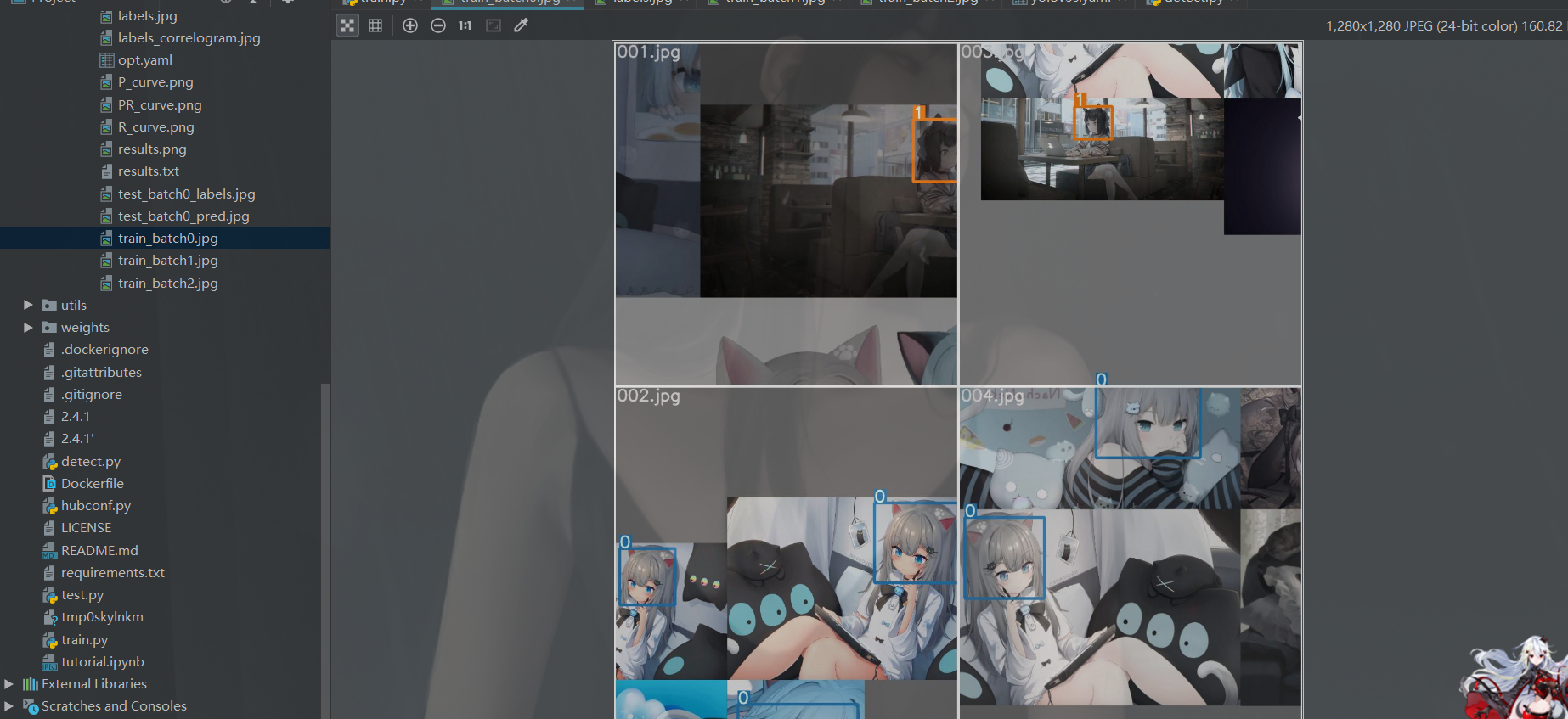
测试
现在咱们测试一下咱们的模型
同样的为了方便,我这里也是直接该参数在文件里面搞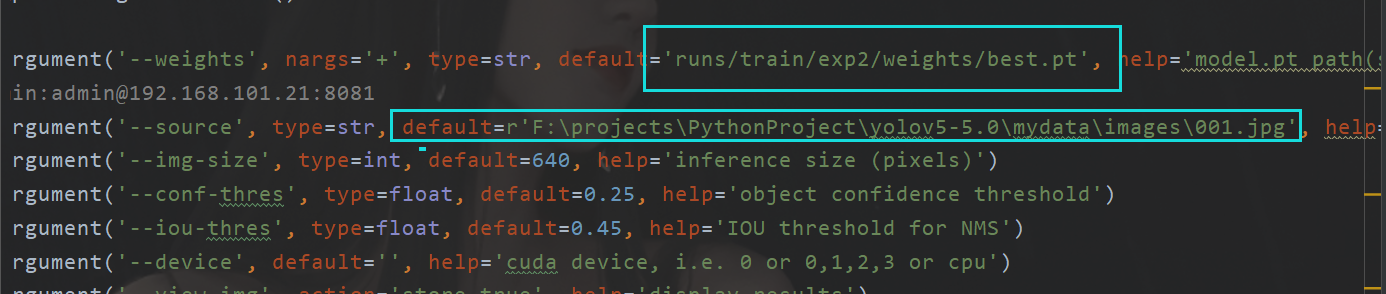
这里的话,一方面是为了方便,还有就是有些超参数我懒得去设置了。
来看看效果:
好框出来了,但是问题来了 问号是什么玩意
- 以下回答由chatgpt基于相关博客总结生成:
很抱歉,根据您提供的参考资料和问题描述,无法确定具体的错误提示和修改的参数。请在提问时提供更详细的错误提示和修改参数等信息,以便给出更准确的解决方案。