python对时间序列栅格数据进行mann-kendall突变检测
背景:python对时间序列栅格数据进行mann-kendall突变检测
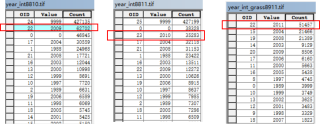
问题:同一组数据,为什么无论如何改变时间长短,突变点在第一年和倒数第二年的像元是最多的?
(例如:检测1988-2010年,则1988和2009年突变的像元最多;检测1999-2005年,则1999年和2004年突变的像元最多)
第一年突变的像元和倒数第二年突变的像元是否有意义?是什么意义?是公式的问题吗?能否直接去掉?
结果:
相关代码:
#用于输出突变点位置(x坐标,即突变年份)的代码
def judge_points(x, y):
pointx = [0]
pointy = [0]
time = list(range(1988, 2011))
# print("time:", time)
n = len(time)
for i in range(n):
if i < n - 1:
# print("time[%s]:"%i,time[i])
x1 = float(time[i]) # 取四点坐标
y1 = float(x[i])
x2 = float(time[i + 1])
y2 = float(x[i + 1])
x3 = float(time[i])
y3 = float(y[i])
x4 = float(time[i + 1])
y4 = float(y[i + 1])
# print("输入:", y1, y2, y3, y4)
k1 = (y2 - y1) / (x2 - x1) # 计算k1,由于点均为整数,需要进行浮点数转化
k2 = (y4 - y3) / (x4 - x3) # 斜率存在操作
b1 = y1 - x1 * k1 # 整型转浮点型是关键
b2 = y3 - x3 * k2
if (k1-k2)!=0:
x0 = (b2 - b1) / (k1 - k2)
else: x0=0
y0 = k1 * x0 + b1
if -1.96 < y0 < 1.96 and time[i] < x0 < time[i + 1]:
pointx.append(x0)
pointy.append(y0)
# print("pointx:", pointx)
# print("pointy:", pointy)
pointx[0] = 1
if pointx[0] == 1:
# print("有")
return pointx[1], pointy[1]
else:
# print("没有")
return 0, 0
#mk突变检验的实现方法
def mktest(inputdata):
inputdata = np.array(inputdata)
n = inputdata.shape[0]
Sk = [0]
UFk = [0]
s = 0
Exp_value = [0]
Var_value = [0]
for i in range(1, n):
for j in range(i):
if inputdata[i] > inputdata[j]:
s = s + 1
else:
s = s + 0
Sk.append(s)
Exp_value.append((i + 1) * (i + 2) / 4)
Var_value.append((i + 1) * i * (2 * (i + 1) + 5) / 72)
UFk.append((Sk[i] - Exp_value[i]) / np.sqrt(Var_value[i]))
Sk2 = [0]
UBk = [0]
UBk2 = [0]
s2 = 0
Exp_value2 = [0]
Var_value2 = [0]
inputdataT = list(reversed(inputdata))
for i in range(1, n):
for j in range(i):
if inputdataT[i] > inputdataT[j]:
s2 = s2 + 1
else:
s2 = s2 + 0
Sk2.append(s2)
Exp_value2.append((i + 1) * (i + 2) / 4)
Var_value2.append((i + 1) * i * (2 * (i + 1) + 5) / 72)
UBk.append((Sk2[i] - Exp_value2[i]) / np.sqrt(Var_value2[i]))
UBk2.append(-UBk[i])
UBkT = list(reversed(UBk2))
return UFk, UBkT
自己解决了。。。
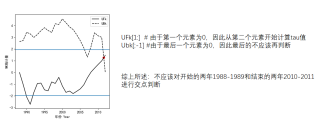
在 Mann-Kendall 突变检测中,检测时段的长度可能会影响结果。针对本问题,可能是因为第一年和倒数第二年突变的像元大量存在,在这两个年份上,由于数据变化可能会存在某些突发事件或者系统问题等,这些数据因素可能会造成这些年份的像元出现大量的突变。这些年份的像元突变所带来的意义需要结合具体情况来分析,可能有一些数据集合并后的问题,从而导致了这些结果。如果经过分析发现这些年份的突变点和数据集本身是无关的,则可直接剔除,否则建议继续进行进一步的分析和讨论。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 以下回答来自chatgpt:
根据问题描述,对于同一组数据,无论时间长度如何改变,第一年和倒数第二年的像元都会出现最多的突变点,而这种现象在MK检验中是不应该出现的。因此需要对问题进行调查与排查。
首先需要检查所使用的代码是否出现问题,例如是否将输入数据处理或读取错误;其次需要检查数据是否存在异常值或缺失值,并进行相应的处理。
如果以上方法未能解决问题,则可以考虑将第一年和倒数第二年的数据去除,然后再进行MK检验。如果新的结果出现了突变点,则可以再次检查数据是否存在问题或考虑采用其他方法进行突变检测。
以下是基于参考资料给出的Python代码示例,用于进行MK检验:
from scipy import stats # 输入数据为一个时间序列矩阵(n x m),其中 n 表示时间序列的长度,m 表示栅格数据的数量 def mk_test(data): n, m = data.shape trend = np.zeros(m) # 保存每个像元的趋势 p_value = np.zeros(m) # 保存每个像元的显著性水平 for i in range(m): x = np.arange(n) y = data[:, i] s, _, _, p, _, _ = stats.mstats.theilslopes(y, x) # 计算单调斜率 trend[i] = s if p < 0.05: p_value[i] = p return trend, p_value其中,使用的是Theil-Sen回归来计算单调斜率,具体可以参考scipy官网。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^