这幅db-RDA图是怎么画的?
这幅图是血清代谢组学运用db-RDA的图,标明了对方差贡献度大的几个代谢物。请问这幅db-RDA的图是怎么做的?为什么横纵坐标是CAP1和MDS1?对方差贡献度大的几个代谢物又是怎么标明出来的,是把代谢物设成环境变量吗?还是用PERMANOVA求出来的?但是如果是用PERMANOVA求出来的怎么能在db-RDA图里标注呢?

该回答引用于gpt与OKX安生共同编写:
- 该回答引用于gpt与OKX安生共同编写:
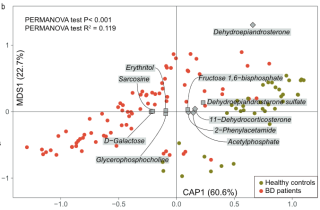
db-RDA(distance-based Redundancy Analysis)是基于距离的冗余分析方法,它在代谢组学研究中常用于分析代谢物数据和环境因子之间的关系。该图显示了通过db-RDA分析得到的CAP1和MDS1坐标下的样本分布情况,其中CAP1和MDS1是通过对距离矩阵进行主坐标分析(PCoA)获得的。
在这幅图中,圆形代表各个样本,颜色表示不同的组别;箭头表示各个环境因子的方向和贡献度大小;分别代表每个代谢物的ID。每个代谢物被视为一个环境变量,并且根据其对样本组别的贡献程度进行排序,然后将前几个代谢物标记在箭头末端的位置上。
具体地,如果您想绘制一个类似的图表,可以按照以下步骤操作:
- 根据所选代谢物的浓度值计算样本之间的距离矩阵。
- 对距离矩阵进行主坐标分析(PCoA),获得CAP1和MDS1的坐标。
- 将代谢物作为环境变量,使用db-RDA方法分析样本和环境因子之间的关系。
- 根据代谢物对样本组别的贡献程度,选择前几个代谢物进行标记。
希望这些信息能够帮助您理解这幅图的绘制过程。