SQL关系除法运算进行购物篮分析
题目:查询囊括了表Items中所有商品的店铺
疑问:不太理解HAVING子句中,等号右边为什么不可以是COUNT(I.items) 为什么要再写一个select子句?
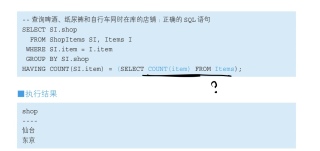
HAVING子句用于过滤掉组后不符合条件的行,通常与GROUP BY配合使用。在查询中,HAVING子句需要比较一个分组条件,这个分组条件是经过COUNT(I.items)函数处理后的数字。如果直接使用COUNT(I.items),SQL可能会产生错误,因为COUNT(I.items)表示的是商品的数量,而不是分组数。
因此,在HAVING子句中使用select子句是为了在分组条件前额外对商品数量进行一次查询,以便与分组条件进行比较。
最终的查询应该是这样的:
SELECT S.shop_name
FROM Shops S
JOIN Items I
ON S.shop_id = I.shop_id
GROUP BY S.shop_name
HAVING COUNT(I.items) =
(SELECT COUNT(*)
FROM Items
WHERE shop_id = S.shop_id)
请注意,这是一种通用方法,对于您具体的需求可能需要进行一些调整。
SELECT COUNT(item) FROM Items -- 仅是查询item不为空的数量
HAVING子句用于过滤掉组后不符合条件的行,通常与GROUP BY配合使用。在查询中,HAVING子句需要比较一个分组条件,这个分组条件是经过COUNT(I.items)函数处理后的数字。如果直接使用COUNT(I.items),SQL可能会产生错误,因为COUNT(I.items)表示的是商品的数量,而不是分组数。
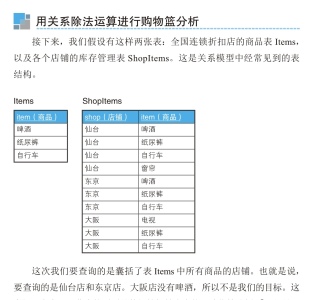
在上面例子中,在等号右边的 COUNT(SI.item) = (SELECT COUNT(item) FROM Items) 中,COUNT(SI.item) 统计了 ShopItems 表中的 item 数量,并与所有 item 的数量进行了比较,以确定当前组内囊括了所有商品。HAVING 子句只显示包含啤酒、纸尿裤和自行车三种商品的店铺。为了确保计数是正确的,在 SELECT 子句中使用了 COUNT(item) 而不是 COUNT(),以计算非空的 item 字段。
是having语句的一个条件,值的来源可以从一个子查询中产生,也可以在前面的select语句中产生。根据需要而定。
在这条语句中Count(SI.ITEM)和Count(i.Item)是永远相等的,如果以此为条件就没意义了
要判断ShopItems里的商品数量等于Items的商品数量,并且Where里过滤掉Items表里没有的item(比如电视),这时就要计算出来Items表里有多少商品(3个),所以加了一个子查询。
HAVING 子句中等号右边不能是COUNT(I.items),因为HAVING子句只允许你使用已经在SELECT 子句中出现过的列。所以,如果你想在HAVING子句中使用COUNT函数,就需要再加上一个select子句来声明你要使用的列,而不是直接使用count函数。
你对于SQL本身的特性和计算规则还是不太了解。
SQL中首先有一条大忌,你不能够一条执行语句里嵌套式的执行聚合函数。就好像你不能这么写:
SELECT COUNT(COUNT(item))
FROM ITEMS
这是一条死规则,那么据此引申,你尝试用等号两端直接等价,本质上和这样的写法类似了:
SELECT CASE WHEN COUNT(item) = COUNT(item) THEN xxx ELSE NULL END -- 仅仅是胡乱举例
这么看,是不是一下就触碰那条规则了?显然这是不行的。那么这条规则的对立面就是“想要执行两条聚合,就要分立不同的执行语句(当然这里指的就是Select”)当按照“ = SELECT COUNT(item) FROM ITEMS”时,本质就还是一个正常的赋值,嵌套做了两遍查询罢了,item表其中元素是否唯一,在实际开发中并不一定知情,如果必要这么写,请强制补充distinct 限定。(顺便吐槽下,业务仓库里,没有这么写查询的,这题仅仅意在秀肌肉和阐述SQL语法格式。)
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇博客也许可以解决你的问题👉 :如何使用 SQL 对数据进行分析?
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
SELECT S.shop_name
FROM Shops S
INNER JOIN Items I ON S.shop_id = I.shop_id
GROUP BY S.shop_name
HAVING COUNT(I.items) = (SELECT COUNT(*) FROM Items);
SELECT S.shop_name
FROM Shops S
INNER JOIN Items I ON S.shop_id = I.shop_id
GROUP BY S.shop_name
HAVING COUNT(I.items) = (SELECT COUNT(*) FROM Items);