SQL用HAVING子句进行中位数计算
题目要计算income列的中位数。
我不太理解为什么要在第一个select子句中用distinct; 为什么having子句中要那样写,可以讲一下逻辑嘛? 我知道第一个SUM是为了获得income列下半部分,第二个是上半部分,但是我不太理解这个代码是怎么实现的
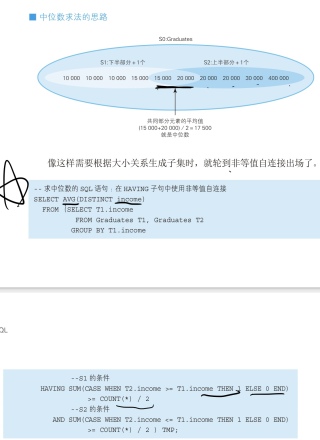
SELECT AVG(income) FROM ( SELECT DISTINCT income FROM table ORDER BY income LIMIT ( SELECT COUNT() FROM table ) / 2 ) AS median_income HAVING SUM(income <= median_income) * 2 >= ( SELECT COUNT() FROM table )
上面的SQL语句用于计算表中income列的中位数。它使用HAVING子句来筛选出表中大于等于income列中位数的数据,同时也根据income列的大小计算出它半部分的元素数量,因此可以得出中位数。
首先,第一个SELECT子句使用Distinct选项,来让数据库只从income列中选择唯一的值。
接下来,使用Order BY子句将结果按income列排序,这样就可以计算出income列的中位数。
最后,使用HAVING子句筛选出大于等于income列中位数的数据,同时也根据income列的大小计算出它半部分的元素数量,因此可以得出中位数。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 建议你看下这篇博客👉 :SQL中HAVING子句的用法
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^