请问这个是怎样回事,有哪位大佬知道吗?
请问这个是怎样回事,有哪位大佬知道吗?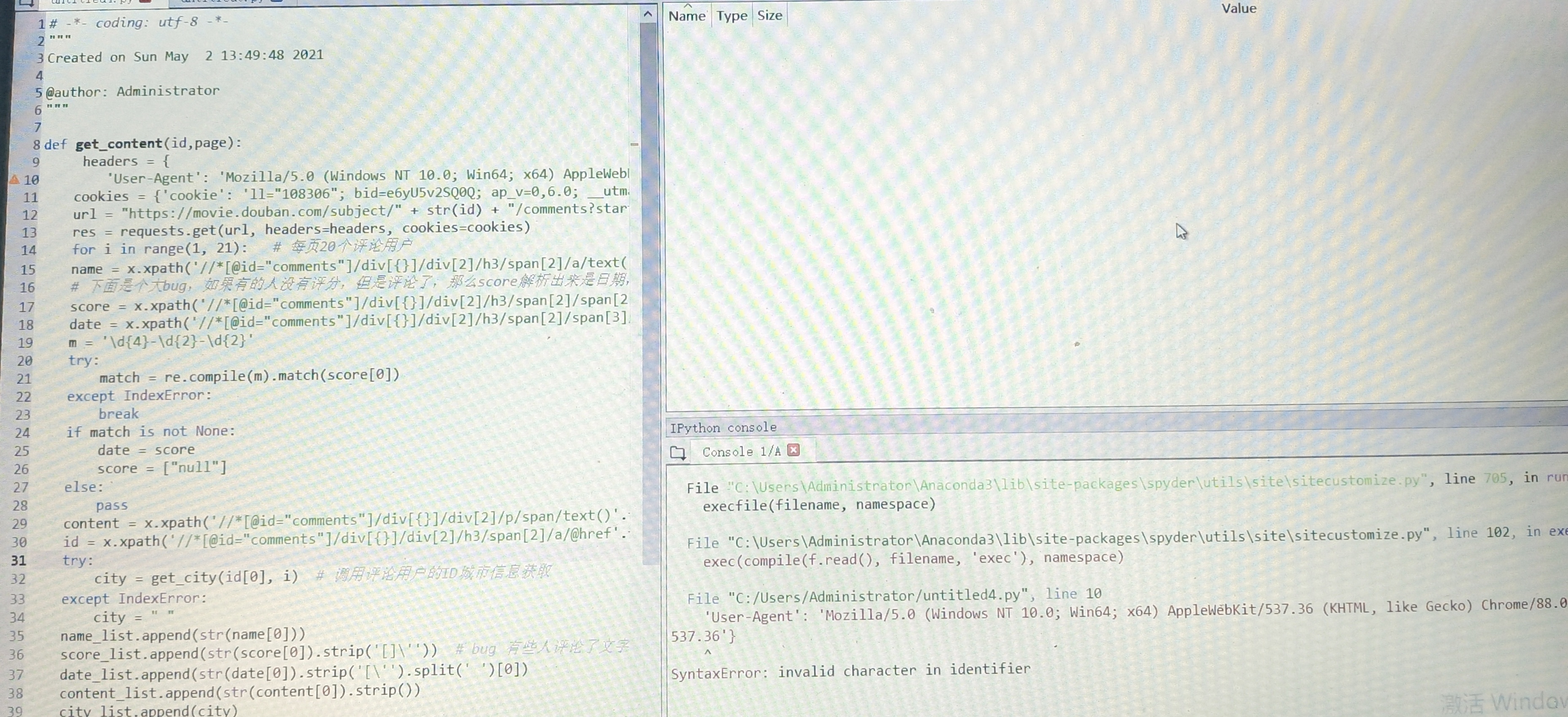
请把代码贴出来。
def get_city(url, i): time.sleep(round(random.uniform(2, 3), 2)) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} cookies = {'cookie': 'bid=Ge7txCUP3v4; ll="108303"; _vwo_uuid_v2=DB48689393ACB497681C7C540C832B546|f3d53bcb0314c9a34c861e9c724fcdec; ap_v=0,6.0; dbcl2="159607750:sijMjNWV7ek"; ck=kgmP; push_doumail_num=0; push_noty_num=0; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1549433417%2C%22https%3A%2F%2Fmovie.douban.com%2Fsubject%2F26266893%2Fcomments%3Fsort%3Dnew_score%26status%3DP%22%5D; _pk_ses.100001.8cb4=*; __lnkrntdmcvrd=-1; __yadk_uid=KqejvPo3L0HIkc2Zx7UXOJF6Vt9PpoJU; _pk_id.100001.8cb4=91514e1ada30bfa5.1549433417.1.1549433694.1549433417'} # 2018.7.25修改, res = requests.get(url, cookies=cookies, headers=headers) if (res.status_code == 200): print("\n成功获取第{}个用户城市信息!".format(i)) else: print("\n第{}个用户城市信息获取失败".format(i)) pattern = re.compile('
.*?(.*?)', re.S) item = re.findall(pattern, res.text) # list类型 return (item[0]) # 只有一个元素,所以直接返回def get_content(id, page): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'} cookies = {'cookie': ' 此处填入自己的cookies,否则不能正常爬取 '} url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit=20&sort=new_score&status=P" res = requests.get(url, headers=headers, cookies=cookies) pattern = re.compile('
.*?
.*?