python爬取电影数据,但excel导出是空的
请问一下,我想爬取电影数据,代码是否正确,如果正确的话为什么导出的excel是空的呀,感谢各位学者的回答!!
import requests
from bs4 import BeautifulSoup
import openpyxl
def get_movie_data(year):
url = f'https://maoyan.com/films?year={year}'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
movies = soup.select('.movie-item-title')
movie_data = []
for movie in movies:
movie_link = 'https://maoyan.com' + movie.a['href']
movie_data.append(get_movie_details(movie_link))
return movie_data
else:
print(f"Failed to fetch data for year {year}")
return []
def get_movie_details(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
movie_name = soup.select_one('h1.name').text.strip()
release_date = soup.select_one('.info-release').text.strip()
genre = soup.select_one('.info-category').text.strip()
director = soup.select_one('.info-director').text.strip()
actors = [actor.text.strip() for actor in soup.select('.info-actor a')]
maoyan_score = soup.select_one('.score-num').text.strip()
box_office = soup.select_one('.info-num').text.strip()
return {
'电影名称': movie_name,
'上映日期': release_date,
'影片类型': genre,
'导演': director,
'演员': ', '.join(actors),
'猫眼口碑': maoyan_score,
'累计票房': box_office
}
else:
print(f"Failed to fetch details for {url}")
return {}
def save_to_excel(data, filename):
wb = openpyxl.Workbook()
ws = wb.active
headers = ['电影名称', '上映日期', '影片类型', '导演', '演员', '猫眼口碑', '累计票房']
ws.append(headers)
for movie in data:
row_data = [movie.get(header, '') for header in headers]
ws.append(row_data)
wb.save(filename)
print(f"Data saved to {filename}")
if __name__ == '__main__':
years = range(2017, 2021)
all_movie_data = []
for year in years:
movie_data = get_movie_data(year)
all_movie_data.extend(movie_data)
save_to_excel(all_movie_data, 'maoyan_movies_2017_to_2020.xlsx')
https://zhidao.baidu.com/question/1903983753830144340.html对你有没有帮助
网址是反爬的,频率太快需要验证。还有你输入的条件没用,网站只有2023的年,其它年份不能查找。
https://www.maoyan.com/films?yearId=18
详情页面是动态网页,用requests是请求不到数据的。
给你个建议吧,在关键的地方写一下输出,就能发现哪一步错了,然后进行修改
问题点:保存没数据
解决方式:第72行代码打印输出,看看有没有数据.
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7430140
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Python进行Excel操作-格式处理和数据排序
- 除此之外, 这篇博客: 用python绘制蒙特卡洛模拟数据折线图中的 研究蒙特卡洛模拟算法,在excel中模拟出了数据变量,需要绘图的时候,excel会卡死,借助python绘图。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
参考如下教程:
python使用matplotlib绘制折线图教程
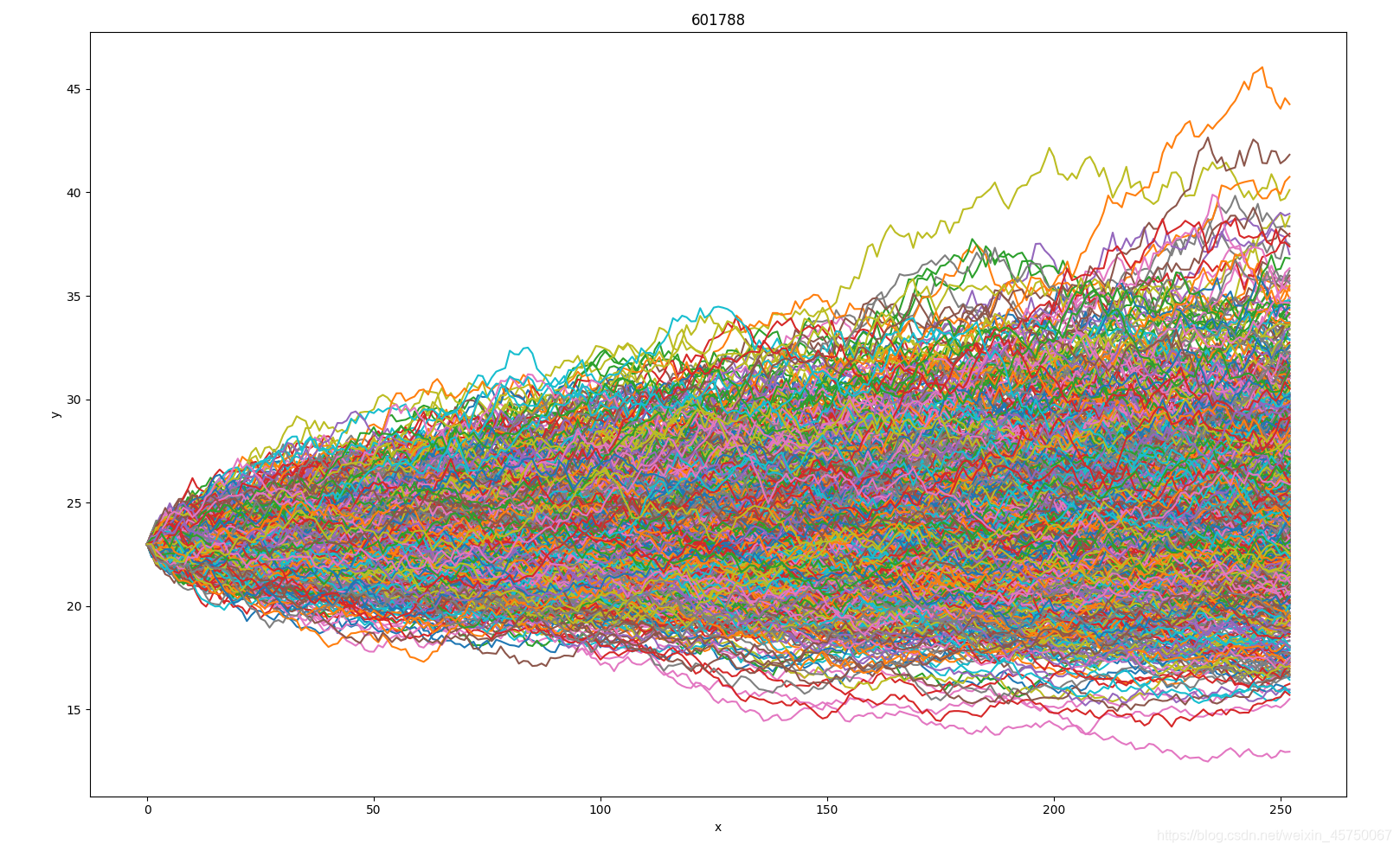
https://www.cnblogs.com/onemorepoint/p/7482644.html没找到上传excel附件的位置,把图片贴出来对数据做一个说明:
第1行为X周,是时间单位,由于是相对时间,所以直接用数字代替
第1列是模拟的次数,总共1000次,每个单元格中的数值为X所对应的y值。
根据以上教程修改后的代码如下:
import matplotlib.pyplot as plt import xlrd y=[[] for i in range(0,999)] workbook=xlrd.open_workbook(r'.\file\price.xlsx') sheet=workbook.sheets()[0] #取每一行数据为y值 for i in (range(0,999)): y[i] = sheet.row_values(i+1) #取第一行数据作为x坐标轴 x = sheet.row_values(0) for i in (range(0,999)): plt.plot(x[1:],y[i][1:]) plt.title('line chart') plt.xlabel('x') plt.ylabel('y') plt.show()运行结果如下:
- 您还可以看一下 曾贤志老师的【曾贤志】用Python处理Excel数据 - 第3季 正则篇课程中的 2.19 贪婪与非贪婪(惰性)小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^