爬取网页数据,结果显示为空如何解决?
我想用python爬取微博热搜榜的数据,思路是先解码网页源代码(decode),再用正则表达式(re)匹配,但是输出显示为空
import requests
import re
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.82"
}
response=requests.get("https://s.weibo.com/top/summary?cate=realtimehot"
,headers=headers)
info=response.content.decode('utf-8','ignore')
content=re.findall(r'<td class="td-02">\s*<a href="(.*?)".target="_blank">(.*?)</a>',info,re.S)
print(content)

请问是哪一步做错了呢?😣
不知道啊。你确定你拿到了网页的信息吗
你的代码看起来基本上是正确的,用于请求和解码网页源代码的部分也没有问题。问题可能出现在你的正则表达式模式上。
在你的正则表达式中,你使用了\s*<a href="(.?)".target="_blank">(.?)的模式来匹配热搜榜的数据。但是,微博热搜榜页面的HTML结构可能会发生变化,导致你的正则表达式无法匹配到正确的内容。
为了确保你的正则表达式可以正确匹配热搜榜数据,建议你使用BeautifulSoup库来解析HTML页面,而不是依赖于正则表达式。BeautifulSoup库可以更方便地提取特定的HTML元素。
以下是使用BeautifulSoup库解析微博热搜榜页面并提取热搜榜数据的示例代码:
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.82"
}
response = requests.get("https://s.weibo.com/top/summary?cate=realtimehot", headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# 找到包含热搜榜数据的元素
table = soup.find('table', class_='data')
# 提取热搜榜数据
content = []
for row in table.find_all('tr'):
cells = row.find_all('td')
if len(cells) >= 2:
link = cells[1].find('a')
if link:
url = link['href']
title = link.text
content.append((url, title))
print(content)
这段代码使用了BeautifulSoup库来解析HTML页面,并通过选择合适的HTML元素和属性提取了热搜榜的链接和标题。你可以根据需要进一步处理和使用这些数据。
请确保已经安装了BeautifulSoup库(可以使用pip install beautifulsoup4命令进行安装),然后尝试运行以上示例代码,看看是否能够成功提取微博热搜榜的数据。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/230563
- 你也可以参考下这篇文章:python解码(decode)的四个参数以及如何使用二进制码和字符之间的转换
- 除此之外, 这篇博客: python编码与解码中的 (decode)是编码的逆向过程。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
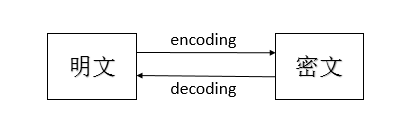
举个例子,这里我们不妨将人类可以很容易理解的字符作为“明文”,将人类的明文加密成不易懂但是更易于存储和传输的消息字节作为“密文”。那么编码和解码的关系如下: 明文就是人类可以直接一眼就看得懂的字符,密文就是明文被加密后一般人无法立马看懂的字节。那为啥要在计算机里面编码解码,多费事啊?
看过《黑客帝国》的都应该记得有个镜头,电脑显示都是0/1字节流动。
那是因为计算机只能识别0和1,而我们人类易于理解的字符没办法直接存储到计算机中。所以必须先将这些字符按照事先规定的方式编码成0/1串才能存储到计算机或者通过网络进行传输(计算机才能识别,才能按照人类想要的操作指令去执行)。当我们从硬盘或者网络中读取文件时,我们读取到的内容全是0/1串(即字节码),当我们打开某个文件其实是被计算机解码后的字符,是需要将这些字节码照一定的方式解码成我们易于理解的明文(即字符),然后我们才能查看或进行相关的处理,不然计算机可以识别的二进制字节码但人类看不懂啊,那你还咋玩呢。同样,人类看的懂的字体符号(即字符),机器看不懂啊,所以你要机器按你的命令执行,那你就得先翻译成机器看的懂的话,它才能乖乖听话不是(这个过程就是编码也)所以人类看的懂的字体符号简称字符,要想让机器看的懂并且按照我们的命令去执行,那就得先编码成机器看的懂的话,也就是编译成字节码,把字符编译成字节的过程叫做编码。
反过来,机器看的懂的话,或者机器按人类的命令操作返回了一些结果,人类看不懂啊,也得进行一次解码,解码成人类看的明白的字体符号(字符),把字节转为人类看的懂的现实生活里面的字符过程就是解码。
编码有一个必要条件是编码的过程不能丢失任何信息,我们能够从密文解码出和原文完全一样的内容。