mysql大数据量使用order by加limit如何优化
目前有一条sql经过时间条件、组织条件过滤后,数据集大概在150万左右,需要对该数据集进行排序取前一百条。目前查询时间为30s,没有在java里处理数据集,想问一问是否有好的优化方案
你每次如果都要获取排序后的前一百条数据,可以考虑分页查询,你的语句也有很大关系,得根据执行计划动态调整
只查询主键id的话多久?
创建合适的索引:确保查询中涉及的列上存在适当的索引。对于 WHERE 条件中的列和 ORDER BY 中的列,创建索引可以加快查询速度。根据查询的具体情况,选择合适的索引策略,如单列索引、联合索引等。
避免全表扫描:尽量避免在大数据集上执行全表扫描。使用合适的索引和条件来缩小查询范围,以避免不必要的数据扫描和排序。
分页缓存:如果数据集是动态变化的,可以考虑使用分页缓存机制。将查询结果缓存在内存中,提高后续查询的性能。
分批处理:将大数据集拆分为多个较小的数据块进行排序和分页处理。可以使用合理的分段条件,每次查询一部分数据,再进行排序和分页操作。
数据预处理:如果查询结果的排序字段是可以提前计算或预先排序的,可以将预处理结果存储在额外的表中,避免每次查询时都进行排序操作。
数据分片和并行处理:如果数据量非常大,可以考虑将数据分片存储在多个节点上,并使用并行处理技术进行查询和排序操作。
考虑优化数据库参数:根据实际情况,适时调整数据库的相关参数,如排序缓冲区大小、临时表空间大小等,以提高排序性能。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/253723
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:记录:如何解决mysql数值型字符串order by排序失效问题【详细】
- 除此之外, 这篇博客: mysql关联查询操作表最新数据中的 方式二:order by 时间 limit 1 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
SELECT * FROM t1_test AS t1 INNER JOIN t2_test AS t2 ON t2.id = ( SELECT t3.id FROM t2_test AS t3 WHERE t3.test_id = t1.test_id AND t3.operate_type = 1 ORDER BY t3.operate_time DESC LIMIT 1 ) WHERE t1.test_id IN (1,5,50,88,99,1666)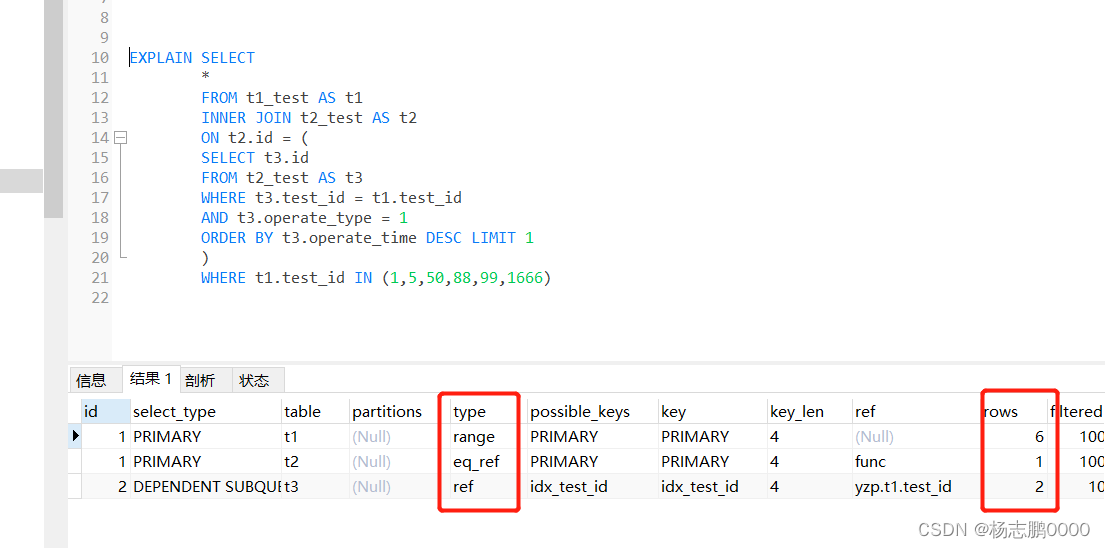
在数据量少时可能没有太多区别,一旦数量量稍微大点,方式一的耗时就可能不是毫秒级的了,建议大家在copy的时候自己也实践一下,究其原因再使用会少很多问题的。最后附上SQL脚本,有兴趣的可以自己测试测试。CREATE TABLE `t1_test` ( `test_id` int NOT NULL AUTO_INCREMENT, `t1_name` varchar(255) DEFAULT NULL, PRIMARY KEY (`test_id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=15004 DEFAULT CHARSET=utf8;CREATE TABLE `t2_test` ( `id` int NOT NULL AUTO_INCREMENT, `test_id` int NOT NULL, `operate_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP, `operate_type` int DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_test_id` (`test_id`) ) ENGINE=InnoDB AUTO_INCREMENT=125056 DEFAULT CHARSET=utf8;新增数据存储过程
CREATE DEFINER=`root`@`localhost` PROCEDURE `test_insert`() BEGIN DECLARE i INT; SET i = 1; WHILE i < 15000 DO INSERT INTO `t1_test` ( `t1_name` ) VALUES ('test999'); SET i = i + 1; END WHILE; ENDCREATE DEFINER=`root`@`localhost` PROCEDURE `test_insert2`() BEGIN DECLARE i INT; SET i = 1; WHILE i < 50000 DO INSERT INTO `t2_test` ( test_id,operate_type) VALUES (i,1); SET i = i + 1; END WHILE; END