想做个读取输入文字合成语音的APP,推荐一款语音引擎?
me是业余选手哈
我知道有现成的APP,但是由于有额外的设计,想自己写一个。
我知道一个:讯飞语音,她好像开始几百条可以免费用,后来需要收费的,而且好像也不太易用。
大家有没有比较好的推荐?
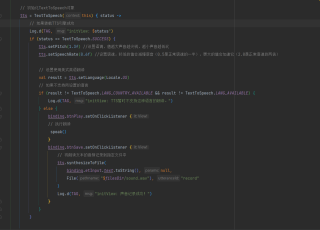
Android自带的TextToSpeech
免费的这个不太现实,道理在于,要联网去做合成的,不像那种离线的库可以做到边际成本为0(免费分发就可以了),它必然有服务器运维的开支(多一个用户就实实在在消耗它的硬件)。真的有免费的,它绝对不可持续,要么做着做着倒闭了,要么等你有了依赖再来收费,逃脱不了这个宿命。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以看下这个问题的回答https://ask.csdn.net/questions/181749
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:APP爬虫过滑块验证码的一种思路, 从此不再依赖打码平台
- 除此之外, 这篇博客: 深聊性能测试,从入门到放弃之:APP性能测试有哪些关注点中的 4.2 开发(架构)工程师角度 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
- 架构设计是否合理
- 数据库设计是否合理
- 代码是否存在性能方面的问题
- 系统中是否有不合理的内存使用方式
- 系统中是否存在不合理的线程同步方式
- 系统中是否存在不合理的资源竞争
- 您还可以看一下 邹积超老师的微信小程序开发实战第三季课程中的 辩论赛计时APP介绍小节, 巩固相关知识点
- 以下回答来自chatgpt:
对于开发语音合成的APP,以下是我给出的解决方案:
推荐使用Google的Text-to-Speech API作为语音引擎。Google的Text-to-Speech API是一款功能强大且易于使用的语音合成引擎,适用于多种平台和语言。它支持多种语音效果和多语言,且提供详细的文档和示例代码,方便开发者集成到自己的应用中。你可以通过Google Cloud的免费账号使用一定量的免费服务,超过免费量后会有一定费用,但相比讯飞语音,费用相对较低。
首先,你需要注册一个Google Cloud账号,创建一个项目并启用Text-to-Speech API服务。然后,根据Google的文档和示例代码,进行API的集成和相关配置。这步需要一些网络请求和认证的代码实现,你可以使用合适的编程语言(比如Python或Java)来完成。
通过调用Text-to-Speech API的接口,将输入的文字发送给API,并接收返回的语音数据。你需要将输入的文字转化为API所支持的数据格式,如SSML或纯文本。通过设置参数,你可以指定语音的声音、音调、语速等效果。
接收到语音数据后,你可以选择将其保存为音频文件,或直接播放出来。如果是保存为音频文件,可以使用合适的编程语言和库来进行文件保存和管理。如果是直接播放出来,可以使用平台所提供的播放器组件或集成第三方的播放器库。
以下是一个使用Python编写的示例代码,演示了如何使用Google Cloud的Text-to-Speech API:
from google.cloud import texttospeech def synthesize_text(text, output_file): client = texttospeech.TextToSpeechClient() synthesis_input = texttospeech.SynthesisInput(text=text) voice = texttospeech.VoiceSelectionParams( language_code="en-US", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL ) audio_config = texttospeech.AudioConfig( audio_encoding=texttospeech.AudioEncoding.MP3 ) response = client.synthesize_speech( input_=synthesis_input, voice=voice, audio_config=audio_config ) with open(output_file, "wb") as out: out.write(response.audio_content) print('Audio content written to file "output.mp3"') # Example usage synthesize_text("Hello, world!", "output.mp3")以上就是一个基本的解决方案,使用Google的Text-to-Speech API来开发语音合成的APP。你可以根据你的具体需求进行进一步的功能开发和界面设计。希望对你有帮助!如果你对具体实现有更多的问题,请随时提问。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^