关于#Java#的问题,如何解决?
Java的语言字典从文件的读取,然后字典的文件打开之后,数据项目不需要唯一,允许重复的代码的思想
可以使用Java的集合框架中的Multimap接口和对应的实现类。Multimap允许一个键对应多个值。
demo 如下, 如有帮助给个采纳谢谢 :
import com.google.common.collect.ArrayListMultimap;
import com.google.common.collect.ListMultimap;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class DictionaryReader {
public static void main(String[] args) {
ListMultimap<String, String> dictionary = ArrayListMultimap.create();
try (BufferedReader reader = new BufferedReader(new FileReader("dictionary.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
String[] tokens = line.split(":");
if (tokens.length == 2) {
String key = tokens[0].trim();
String value = tokens[1].trim();
dictionary.put(key, value);
}
}
} catch (IOException e) {
e.printStackTrace();
}
// 输出整个字典
for (String key : dictionary.keySet()) {
System.out.println(key + ": " + dictionary.get(key));
}
// 获取特定键的所有值
String keyToGet = "example";
if (dictionary.containsKey(keyToGet)) {
System.out.println("Values for key '" + keyToGet + "': " + dictionary.get(keyToGet));
} else {
System.out.println("Key not found: " + keyToGet);
}
}
}
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7482396
- 你也可以参考下这篇文章:【Java习题程序】输入一个英文单词顺序,反转句子中单词的顺序,但单词内字符的顺序不变。
- 同时,你还可以查看手册:java-学习Java语言 - 描述Java编程语言的基本概念和特点的课程。-泛型是Java编程语言的一个强大功能。它们提高了代码的类型安全性,使更多的错误可以在编译时发现。-野生动物 中的内容
- 除此之外, 这篇博客: 【Java】爬虫,能不能再详细讲讲?万字长文送给你!中的 获取新闻内容与评论内容 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
注意到新闻列表里,我们主要拿到了下面5个属性
String title; // 新闻标题 String docurl; // 新闻链接 String commenturl; // 评论链接 String time; // 新闻发布时间 List<Keywords> keywords;// 新闻关键词你会发现,新闻链接进去之后,新闻内容是静态的,不需要二次加载,因此使用Jsoup获取即可。此处略去。
还有一点要说明,就是新闻列表里的标题和关键词不一定是完整的,所以,要想获取确保完整的新闻标题和关键词,最好还是去新闻详情页获取。同样,都是静态内容,技术较为简单,此处略去。
关键是新闻评论,评论是动态加载的。因此我们还需要再次进行“抓包”!
进入评论链接 ==> 按下F12 并选中Network ==> 刷新页面 ==> 点击Type ==> 逐个查看script的Preview,可以发现有3个script非常可疑!
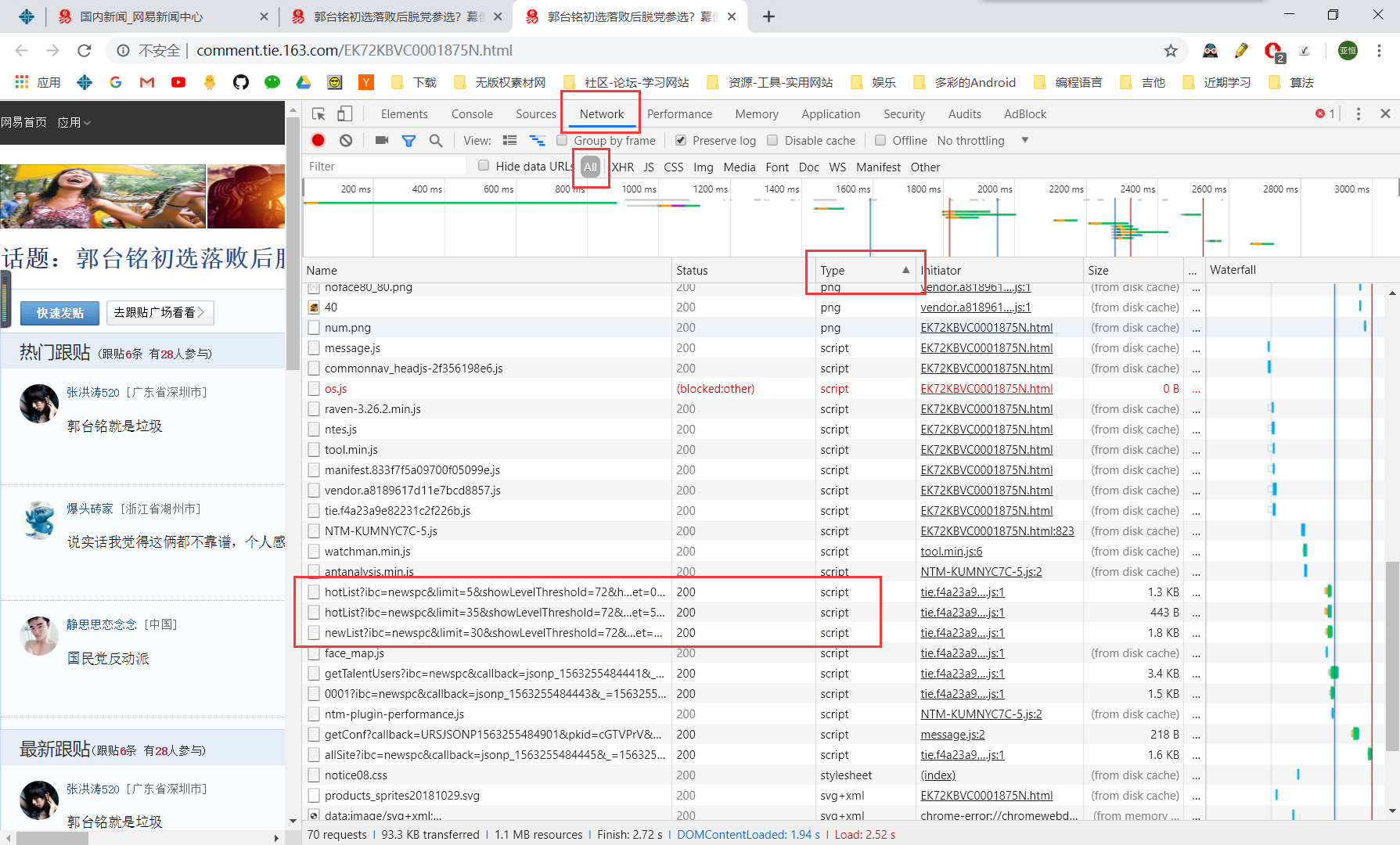
点击一下,查看Preview,果真是评论。
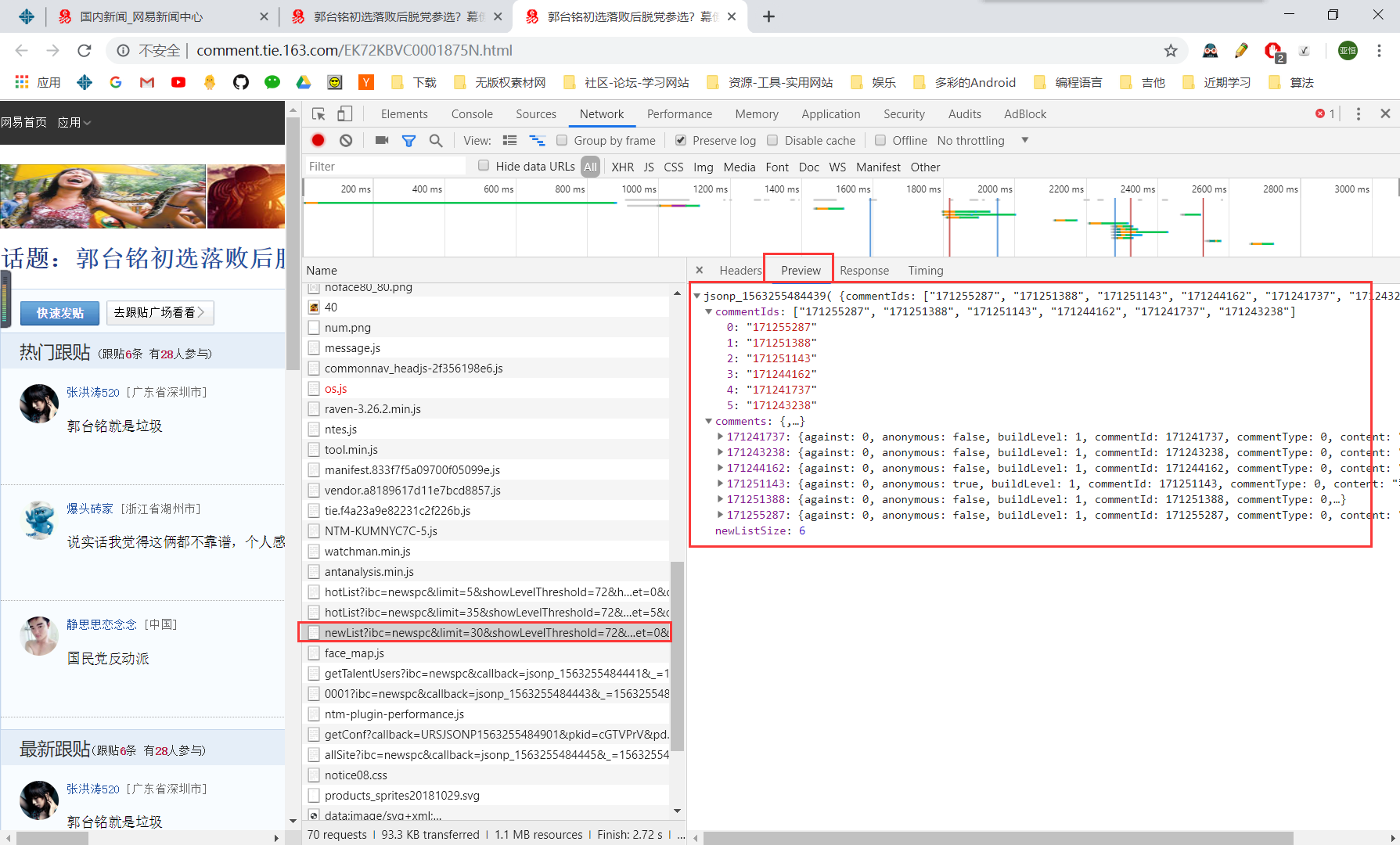
再次将这三个script的链接复制下来找规律,两个hotList,一个newList,我已经把变化找到了

我们老师思考了一整天,发现最后变化的是将系统时间转化成秒数,然后递增1。我试验了一下,确实是。不过,经过我和我的小伙伴的探索,发现,很多参数都没有用。在彻底理解这个URL链接的作用后,我专门发表了一个说说:

经过简化,整个URL其实只需要两个参数limit和offset即可拿到评论:http://comment.api.163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/EK72KBVC0001875N/comments/newList?limit=30&offset=0如果你接触过Mysql的分页查询,对这两个参数应该不陌生
offset就是偏移起始量,limit是偏移量,规律如下:
limit=30&offset=0 // 从0开始,往后取30条数据,得到[0-29] limit=30&offset=30 // 从30开始,往后取30条数据, 得到[30-59] limit=30&offset=60 // 从60开始,往后取30条数据, 得到[60-89] limit=30&offset=90 // 从90开始,往后取30条数据, 得到[90-119] ......你可以手动在浏览器地址栏进行尝试,会发现每次取得数据都不一样。经过对比查看,我们会发现,newList中的内容包含两个hotList中的内容,这也符合常理,我们在最新评论中选取点赞量高的让其成为最热评论。不过,为了避免重复,我们只拿newList中的内容即可。
但是,等等,我们是不是又忽略了一个重要的事情,就是,怎么才能获取到响应的url?
两种方式:一、手动“抓包”,然后写死在程序中。二、手动“抓包”,然后使用cdp4j进行获取Network响应URL。
为了锻炼锻炼我的正则表达式 能力,我依然选择了后者。还是通过官方给的样例
NetworkResponse.java 主要代码如下:
// 获取网络响应内容,通过正则得到评论的json地址 public static List<String> getCommentJsonUrlListFromUrl(final String url, int commentCount) { Launcher launcher = new Launcher(); List<String> commentJsonUrlList = new ArrayList<>(); try (SessionFactory factory = launcher.launch(asList("--disable-gpu", "--headless"))) { String context = factory.createBrowserContext(); try (Session session = factory.create(context)) { // 连通网络 session.getCommand().getNetwork().enable(); // 事件监听器 session.addEventListener(new EventListener() { @Override public void onEvent(Events event, Object value) { if (NetworkResponseReceived.equals(event)) { ResponseReceived rr = (ResponseReceived) value; Response response = rr.getResponse(); // 从response对象中获得url String commentJsonUrl = response.getUrl(); String originCommentJsonUrl = commentJsonUrl; // 正则匹配,检测网站 https://regex101.com 匹配3条约用时2ms Pattern pattern = Pattern.compile(".*newList\\?ibc.*"); Matcher matcher = pattern.matcher(commentJsonUrl); if (matcher.find()) { // 页码总数 = 评论总数 / 每页显示个数 int pageCounts = commentCount / 30; for (int i = 0; i <= pageCounts; i ++) { // offset 译为 偏移起始点, limit = 30 为 偏移量 commentJsonUrl = commentJsonUrl.replaceFirst("offset\\=[0-9]+", "offset=" + i*30); commentJsonUrlList.add(commentJsonUrl); } } } } }); // 监听器写在导航之前 // 一定要有连接超时设置,且不小于2s(多次测试得出结论,具体时间和网速有关系),否则无法获取 session.navigate(url).wait(5 * 1000).waitDocumentReady(5 * 1000); } // 处理浏览器上下文,源码:contexts.remove(browserContextId) factory.disposeBrowserContext(context); } // 关闭后台进程,由于历史原因,关闭进程习惯使用kill launcher.getProcessManager().kill(); return commentJsonUrlList; }上面的代码中,我们一开始传入两个参数,一个是该新闻的评论链接,另一个是评论的总数。
评论链接我们已经在新闻列表中获取到了。关键是评论的总数,因为我们要计算后台到底分了多少页,这样才能拿到全部评论。很不幸,这个评论总数是动态加载的,无法使用Jsoup获取到,但不要紧,cdp4j可以呀!使用cdp4j可以轻松的获取到新闻详情渲染后的页面。然后使用xPath或者CSS选择器拿到评论总数即可。
通过上面的代码,我们就能拿到评论所有分页的链接,之后就是使用Jsoup获取静态的Json数据了,方法和获取Network响应的新闻列表JSON串相似,此处略去。
- 您还可以看一下 汪翠老师的java项目实战之欢乐斗地主游戏开发教程 毕业项目课程设计带源码课程中的 给扑克牌绑定鼠标事件实现单击可以选择出牌列表小节, 巩固相关知识点
- 以下回答来自chatgpt:
背景和上下文信息:
在我的Java项目中,我需要从一个字典文件中读取数据项,并且这些数据项可能会重复出现。这个字典文件是一个文本文件,每一行都是一个数据项。我需要将这些数据项加载到内存中,并对它们进行操作。
问题解决方案:
针对这个问题,我可以使用Java中的HashMap数据结构来处理。HashMap可以存储键值对,其中键是唯一的,每个键只能对应一个值。所以,只需要将重复的数据项当作键存储,并将值设为任意非null的值即可。
具体的代码实现如下:
import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.util.HashMap; import java.util.Map; public class ReadDictionary { public static void main(String[] args) { String fileName = "dictionary.txt"; Map<String, Integer> map = new HashMap<>(); try (BufferedReader br = new BufferedReader(new FileReader(fileName))) { String line; while ((line = br.readLine()) != null) { String key = line.trim(); if (!map.containsKey(key)) { map.put(key, 1); } else { int value = map.get(key); map.put(key, value + 1); } } } catch (IOException e) { e.printStackTrace(); } System.out.println("Total items: " + map.size()); for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + ": " + entry.getValue()); } } }这段代码首先创建了一个HashMap对象,并在读取字典文件时,将每个数据项作为键存储到HashMap中。如果该键已经存在,则获取其原有的值,将其加1,并更新HashMap中该键对应的值。最后,输出HashMap中的键值对。
如果字典文件很大,可能需要考虑分批读取文件,以减少内存占用。也可以尝试使用更高效的HashMap实现,如Fastutil或Trove。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^