用scrapyd部署scrapy异步调度
源于这个问题 https://blog.csdn.net/jerrism/article/details/108003456
你想解决这个异步调度问题嘛
- 这篇文章:scrapyd部署各种问题 也许能够解决你的问题,你可以看下
- 除此之外, 这篇博客: scrapy框架中的 scrapyd的安装 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
scrapyd服务:(在服务器安装)
pip install scrapydscrapyd客户端:(在客户端安装)
pip install scrapyd-clientscrapyd的配置文件
# [root@scrapy gerapy]# vim /etc/scrapyd/scrapyd.conf [scrapyd] eggs_dir = eggs logs_dir = logs items_dir = jobs_to_keep = 5 dbs_dir = dbs max_proc = 0 max_proc_per_cpu = 4 finished_to_keep = 100 poll_interval = 5.0 bind_address = 127.0.0.1 http_port = 6800 debug = off runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus启动scrapyd服务
在scrapy项目路径下 启动scrapyd的命令:
sudo scrapyd或scrapyd启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面
部署爬虫项目到scrapyd
编辑scrapy.cfg文件:
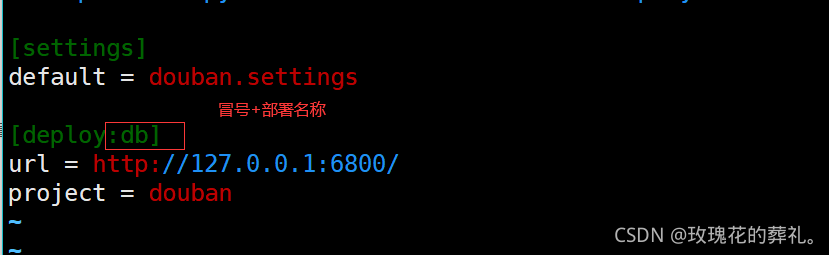
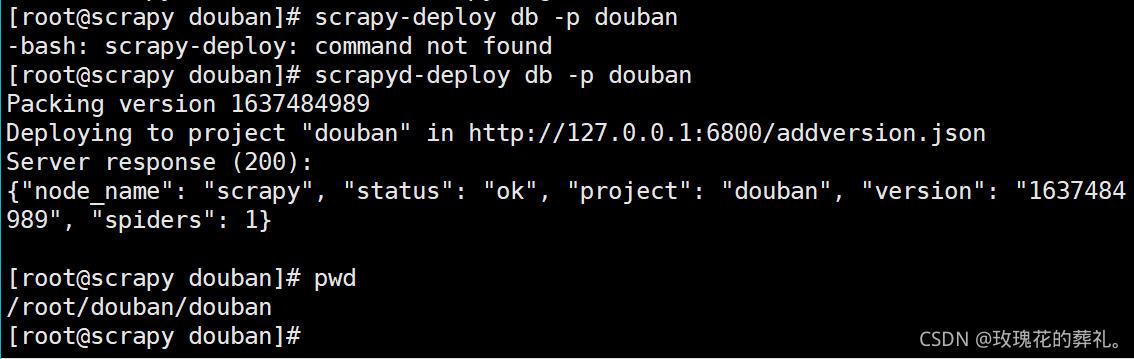
注意 -p选项的名称可随意,如果部署到服务器(gerapy)报错,修改代码重新部署
,
管理scrapy项目
启动项目:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
关闭项目:
curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid使用requests模块控制scrapy项目
import requests # 启动爬虫 url = 'http://localhost:6800/schedule.json' data = { 'project': 项目名, 'spider': 爬虫名, } resp = requests.post(url, data=data) # 停止爬虫 url = 'http://localhost:6800/cancel.json' data = { 'project': 项目名, 'job': 启动爬虫时返回的jobid, } resp = requests.post(url, data=data)小结:
- 在scrapy项目路径下执行
sudo scrapyd或scrapyd,启动scrapyd服务;或以后台进程方式启动nohup scrapyd > scrapyd.log 2>&1 & - 部署scrapy爬虫项目
scrapyd-deploy -p myspider - 启动爬虫项目中的一个爬虫`curl http://localhost:6800/schedule.json -d project=myspider -d spider=tencent
重新部署吧
Scrapy 部署不用愁,Scrapyd 的原理和使用
基于new bing部分指引作答:
要使用Scrapyd部署Scrapy异步调度,你可以按照以下步骤进行操作:
确保已经在系统中安装了Scrapyd和Scrapy。你可以使用命令行运行
pip install scrapyd scrapy来安装它们。在你的Scrapy项目中创建一个Scrapyd配置文件。可以在项目根目录下创建一个名为
scrapyd.conf的文件,并写入以下内容:
```
[settings]
default = your_project_name.settings
[deploy:local]
url = http://localhost:6800/
project = your_project_name
这里将`your_project_name`替换为你的Scrapy项目的名称。
3. 在命令行中进入到你的Scrapy项目根目录,并执行以下命令启动Scrapyd服务:
scrapyd
4. 接下来,在你的项目根目录中执行以下命令将项目部署到Scrapyd:
scrapyd-deploy local -a
这会将你的项目打包并部署到本地Scrapyd服务。
5. 部署成功后,你可以通过访问`http://localhost:6800/`来查看Scrapyd的Web界面。在这里,你可以管理和控制已部署的Scrapy项目。
6. 要调度Spider运行,可以发送HTTP POST请求到Scrapyd的API接口。例如,通过发送以下命令来启动爬虫:
curl http://localhost:6800/schedule.json -d project=your_project_name -d spider=your_spider_name
```
将your_project_name替换为你的Scrapy项目名称,your_spider_name替换为你要运行的Spider名称。
这样,你就可以使用Scrapyd来部署和调度Scrapy的异步任务了。希望能对你有所帮助!
具体报了什么错误呢。你提供的连接中提到了遇到问题的解决方法就是:手动安装AsyncioSelectorReactor先在settings.py中注释对TWISTED_REACTOR的设置,然后手动安装reactor。这样操作不行是么。
报什么错误信息没,手动安装AsyncioSelectorReactor试试
爆了啥错,粘一下