scrapy框架加上selenuim
scrapy框架加上selenuim爬虫时各部分已完成,xpath定位准确,爬出来却是none值
相同的定位方式,第一个爬的出来,第二个和以后则是none值
利用绝对路径也能爬出来


- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/1091167
- 这篇博客你也可以参考下:scrapy爬取信息时xpath组装多个标签的信息值
- 除此之外, 这篇博客: Scrapy入门爬取博客园新闻中的 xpath选择器 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
简介:xpath使用路径表达式在xm和htm中进行导航
语法:
spider中使用xpath示例
博客园-新闻文章
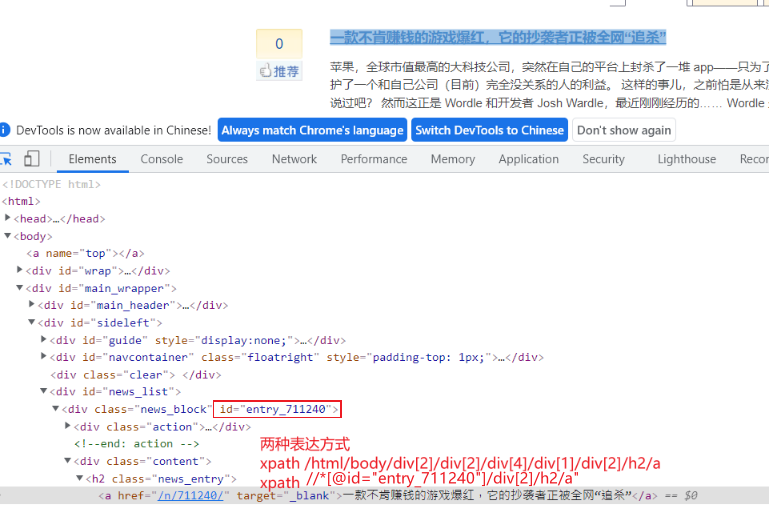
spider中提取信息 /n/711240/
url = response.xpath('//*[@id="entry_711240"]/div[2]/h2/a/@href').extract_first(""); // 提取id=entry_711240 下第二个div中h2中a标签的href属性;extract_first("")表示取第一个,不存在则赋值""空。显然,使用这种xpath方法写法是固定死的,需要修改。
观察发现,不同文章的url是不同的,因此第一步是提取出各个文章的 /n/xxxxxx/
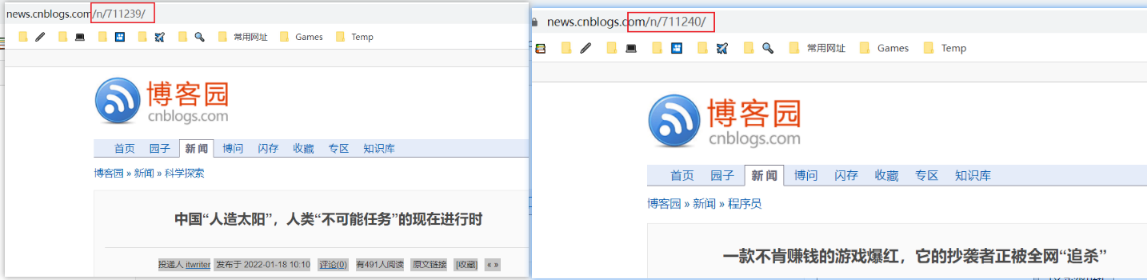
使用开发者模式观察/n/xxxxx/的位置
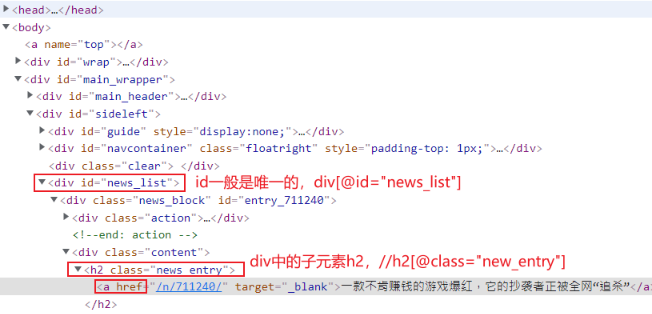
编写代码提取出该页面的所有 /n/xxx/ 信息列表
def parse(self, response): url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract() 效果图

如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^