利用kmeans或kshape聚类分析对归一化的无量纲时间-降雨序列进行聚类
#求帮助#如何利用kmeans或kshape聚类分析对归一化的无量纲时间-降雨序列进行聚类(分类,区分降雨雨型的差异),主要需要相关的代码最好是python代码(jupter notebook,python3.10),可调用相关机器学习库
对多次降雨事件归一化后的无量纲 时间-降雨序列曲线如下图所示:
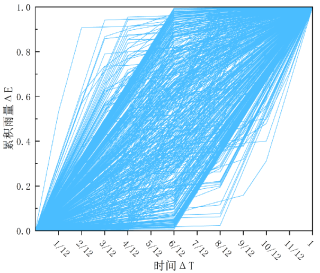
具体分类的原因和目的可参照这篇论文:Stochastic generation of daily rainfall events: A single-site rainfall model
with Copula-based joint simulation of rainfall characteristics and
classification and simulation of rainfall patterns
聚类的结果类似下面这样,5-7种
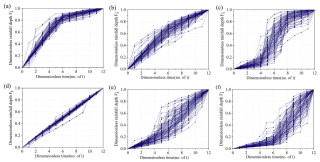
归一化数据可由以下链接下载通过百度网盘分享的文件:归一化结果.xl…
链接:https://pan.baidu.com/s/16T2NZaKBgNbw9W4c7HoAyw
提取码:mu5r
有没有数据集 发下
对于利用K-means或KShape聚类分析归一化的无量纲时间-降雨序列进行聚类,您可以按照以下步骤进行:
- 准备数据:首先,您需要将归一化的无量纲时间-降雨序列加载到Python中。您可以使用相关库(如pandas)读取Excel文件中的数据,并将其转换为适合聚类分析的数据格式。
- 数据预处理:在进行聚类分析之前,通常需要进行数据预处理。您可以根据需要对数据进行降维、特征选择等处理。如果您的数据集较大,您可以考虑使用主成分分析(PCA)等方法来减少数据的维度。
- 选择聚类算法:根据您的需求,选择适合的聚类算法。对于K-means聚类,您可以使用scikit-learn库中的KMeans类。对于KShape聚类,您可以使用相关的库(如tslearn)来实现。
- 执行聚类分析:根据所选的聚类算法,对数据进行聚类分析。根据您提供的信息,您可以尝试使用K-means或KShape算法。在执行聚类之前,您需要确定要分为多少个类别(例如,5-7个)。
- 可视化结果:完成聚类分析后,您可以通过绘制图表或图形来展示聚类结果。您可以使用Matplotlib等库来可视化聚类结果,并观察不同类别之间的差异。
以下是一个简单的示例代码片段,演示了如何使用scikit-learn库进行K-means聚类分析:
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取数据
data = pd.read_excel('归一化结果.xlsx')
# 2. 数据预处理(如果需要)
# 3. 执行聚类分析
k = 5 # 聚类数目
kmeans = KMeans(n_clusters=k)
kmeans.fit(data)
# 4. 获取聚类结果
labels = kmeans.labels_
# 5. 可视化聚类结果
plt.scatter(data['时间'], data['降雨量'], c=labels)
plt.xlabel('时间')
plt.ylabel('降雨量')
plt.title('K-means聚类结果')
plt.show()
根据您的具体需求和数据特点,您可能需要对代码进行进一步调整和优化。请根据实际情况选择合适的聚类算法,并根据您的数据集进行必要的预处理和可视化操作。