Python 文件读取
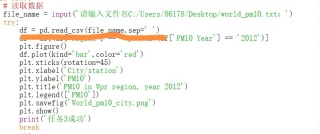
为什么把sep=‘ ’换成encoding=‘cp936’会显示任务执行失败
引用chatgpt部分指引作答:
将sep参数从' '(空格)更改为'cp936'会导致任务执行失败是因为这是错误的用法。sep参数用于指定分隔符,而encoding参数用于指定文件的编码格式。
当使用pd.read_csv函数读取文件时,sep参数用于指定分隔符,以便正确地解析文件中的列。常见的分隔符包括逗号(,)、制表符(\t)等。
encoding参数用于指定文件的编码格式。编码格式是决定如何将文件中的字节序列解码为文本字符的规则集。常见的编码格式包括UTF-8、ASCII、cp936(又称为GBK)等。
如果你的文件以空格作为分隔符,并且编码格式是cp936(GBK),你应该同时指定这两个参数,而不是将其中一个替换为另一个。示例代码如下:
df = pd.read_csv(file_name, sep=' ', encoding='cp936')
这将使用空格作为分隔符,并将文件解码为使用cp936编码格式的文本字符。
请确保你提供的参数值正确,包括文件名和文件的实际编码格式。
基于new bing的编写,你改成这个的目的是什么?:
encoding='cp936' 是指定文件编码方式为 GBK 或者 GB2312,而不是指定数据的分隔符。如果你的数据里面使用的是空格分隔符,在读取数据的时候需要将 sep 参数设置为 " ",而不是 "cp936"。
在你的代码中将 sep 参数设置为 "cp936" 是非法的,因此执行代码会导致出错,无法成功执行任务。
你要理解这两个不同参数的含义
seq表示字段之间的分割符
encoding表示文件内容的编码方式
这两个参数是完全不同的,不能替换df = pd.read_csv(file_name, sep=' ', encoding='cp936')可以指定参数来覆盖默认的参数
创作不易, 如果对你有帮助辛苦给个采纳谢谢 , 也欢应咨询其他py 相关问题encoding 指的是编码格式 , 你把encoding= ‘cp936’ 换成 encoding='utf-8' 就好了
举例如下<这是一个读取云南大学介绍的,并采用结巴词库进行 分词统计的案例, 可以直接拿去用>:
import jieba
# 读取文本
with open('云南大学.txt', 'r', encoding='utf-8') as f:
text = f.read()
# 对文本进行分词
words = jieba.cut(text)
# 统计每个词语的出现次数
word_count = {}
for word in words:
if len(word) > 1 and word not in ['高校', '大学']:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
# 对词语出现次数进行排序
sorted_word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
# 输出前20项
for i in range(20):
print(sorted_word_count[i][0], sorted_word_count[i][1])
你会发现 读取这里我用的就是 utf-8 的编码
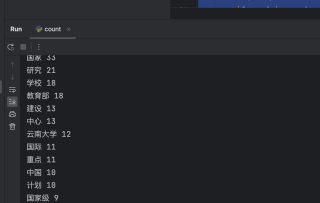
输出截图如下 :
要搞清楚为什么会有这个错误,首先要明确这两个参数的作用,sep用于指定数据之间的分隔符,csv文件默认是英文的逗号,如果你的数据文件是txt的,那么要检查下数据是空格还是逗号隔开,逗号隔开的就是指定sep=' ' 否则默认会认为是逗号隔开的,所以sep参数在数据文件是txt 且数据之间是以空格隔开的情况下必须指定。其次, encoding用于指定文件的数据编码,一般设置为utf-8 表示数据中有中文字。这两个参数可以同时使用,参数的值怎么设置,视数据文件具体情况而定
把这个encoding ='cp936'换成 encoding ='utf -8'应该行,我感觉现在都用UTF-8这个格式
txt文件是用什么编码格式弄的,应该是utf-8,没有人会特意改变的,sep=‘ ’(TXT文件没有固定的列分隔符),encoding=‘cp936’(是GBK格式的),你换成utf-8试试呢
sep和enconding可以一起使用
如果你是想去除乱码,可以使用这个
encoding='utf-8'
读取的csv中可能有未知的行/列,因此需要设定sep参数.sep参数和encoding是完全不同的,可以尝试使用
with open(file_name,encoding='cp936') as file:#可能encoding需要UTF-8
data=pd.read_csv(file,sep='')
哈哈 我上周也遇到了这个问题。分享给你:
把sep参数改为encoding参数有问题,因为这两个参数是用来完成不同的任务的。sep参数指定了CSV文件中数据项之间的分隔符,例如\t、,或;等等,它是用来解析CSV文件的。encoding参数则是指定文件的编码方式,例如utf-8、gbk、cp936等等,它是用来读取文本文件的。
如果你把sep参数改为encoding,会导致Python解释器无法解析文件中的数据,因此会出现任务执行失败的情况。正确的做法应该是根据实际情况选择正确的分隔符和编码方式,例如:
df = pd.read_csv(file_name, sep=';', encoding='utf-8')
这里假设CSV文件的分隔符为;,编码方式为utf-8,你可以根据实际情况进行替换。