Python,为什么我照着书上的输入函数是错误的
学到函数这里,照着书上的例子试了一下,但是是错的,检查了好几遍也没漏掉什么,怎么回事啊?
还有我的Python为什么关键字不是彩色的呀?一片黑的看的好累

你能把代码贴出来吗,你能用python 的IDE去写吗,你用命令窗口有个啥的关键词
代码贴出看看
这是缩进不对,比如说 return 写在和 def 函数名一列了,特别注意空格和tab看上去差不多,但是如果不一致,也会报错。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7707086
- 这篇博客你也可以参考下:Python关于服务器与客户端交互,登录验证,删除修改密码等操作的简单实现,自定义协议与协议函数的实现
- 同时,你还可以查看手册:python- 位置或关键字参数 中的内容
- 除此之外, 这篇博客: Python对列表中的数字快速排序,并且得到排序后的缺失数据。中的 Python对列表中的数字进行排序,并且排序后找出从左到右第一个丢失的数据。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
结果如下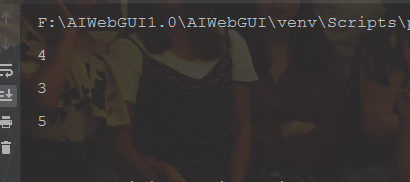
num_list 中 排序完成后缺少4
num_list1 中 排序完成后缺少3
num_list2 中 排序完成后缺少5代码如下
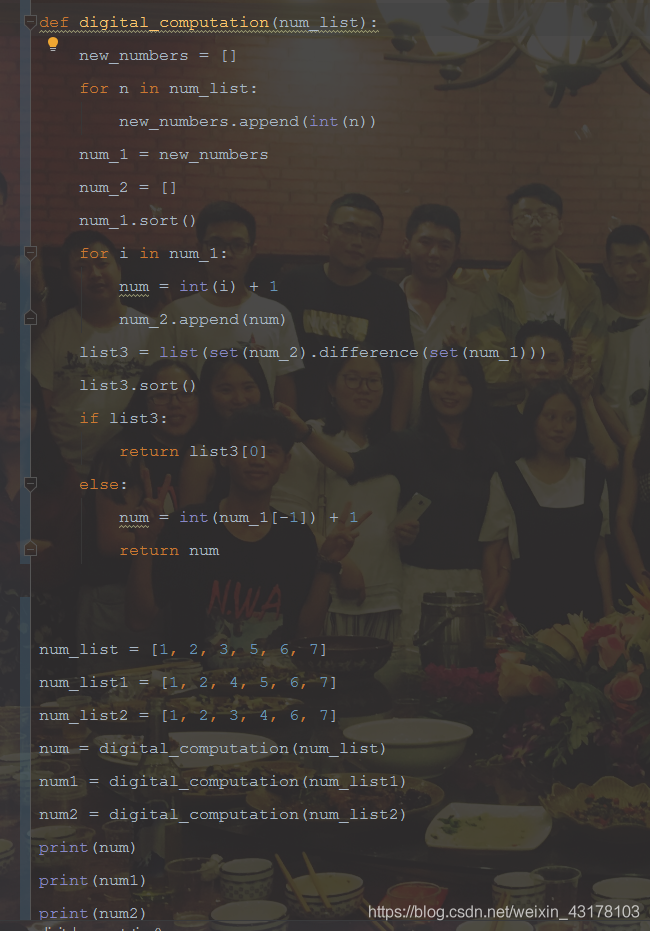
def digital_computation(num_list): new_numbers = [] for n in num_list: new_numbers.append(int(n)) num_1 = new_numbers num_2 = [] num_1.sort() for i in num_1: num = int(i) + 1 num_2.append(num) list3 = list(set(num_2).difference(set(num_1))) list3.sort() if list3: return list3[0] else: num = int(num_1[-1]) + 1 return num num_list = [1, 2, 3, 5, 6, 7] num_list1 = [1, 2, 4, 5, 6, 7] num_list2 = [1, 2, 3, 4, 6, 7] num = digital_computation(num_list) num1 = digital_computation(num_list1) num2 = digital_computation(num_list2) print(num) print(num1) print(num2)- 您还可以看一下 CSDN就业班老师的Python爬虫技术和浏览器模拟,验证码识别视频教程课程中的 网络爬虫实战小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
针对第一个问题,如果照着书上的例子输入出现错误,建议检查书上的例子是否存在笔误或者遗漏的逗号、括号等符号。如果检查过多次仍无果,则需要思考是否存在语法或者逻辑上的问题,可以参考官方文档、Stack Overflow等网站寻找解决方法。
针对第二个问题,如果Python编辑器中关键字没有高亮显示,建议检查编辑器是否支持Python语言,并且是否需要在编辑器的设置中开启该功能。可以在编辑器的官方网站或者使用手册中查找具体方法。同时,建议使用支持代码高亮、调试、自动补全等功能的专业Python编辑器,如PyCharm、Sublime Text等。
对于第三个问题,如果需要对输入进行非法情况过滤,可以在函数中使用try-except语句捕捉输入的异常。具体步骤如下:
- 在函数中使用while语句不断循环,直到输入的数据合法
- 在循环中使用try-except语句捕捉输入的异常,如果输入的数据不合法,在except语句中提示用户重新输入
- 当输入的数据合法后,跳出循环,执行后面的逻辑代码
以下为示例代码:
def input_score(): while True: try: score = float(input("请输入分数:")) except ValueError: print("输入非法,请重新输入!") continue if score < 0 or score > 100: print("输入非法,请重新输入!") continue else: return score break score = input_score() print("您输入的分数是:", score)对于第四个问题,如何获取当前页面的网页数据、通过xpath的方式提取出对应的超链接、获取详情页面的数据、将数据保存在docx文档等问题,可以参考网络爬虫相关的知识。具体步骤如下:
- 使用Python的Requests库向目标页面发送请求,获取页面的数据
- 使用XPath或BeautifulSoup等库解析页面的HTML代码,通过定位页面元素获取超链接等相关信息
- 使用Python的Requests库再次向目标页面发送请求,获取详情页面的数据
- 使用XPath或BeautifulSoup等库解析详情页面的HTML代码,通过定位页面元素获取需要的数据
- 使用Python的docx库创建文档文件,按照需要的格式将数据保存在docx文档中
以下为示例代码(注意需要根据具体需要进行修改):
import requests from lxml import etree from docx import Document def get_data(url): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"} response = requests.get(url, headers=headers) data = etree.HTML(response.text) href_list = data.xpath("//div[@class='e-img']/a/@href") img_list = data.xpath("//div[@class='e-img']/a/img/@src") for href, img in zip(href_list, img_list): img = requests.get("https://www.csflhjw.com" + img, headers=headers).content f = open("1.jpg", "wb") f.write(img) res = requests.get("https://www.csflhjw.com" + href, headers=headers) html = etree.HTML(res.text) name = html.xpath('//div[@class="team-e"]/h2/text()')[0] edu = html.xpath('//div[@class="team-e"]/p[1]/text()')[0] profession = html.xpath('//div[@class="team-e"]/p[2]/text()') sponsa = html.xpath('//div[@class="team-e"]/p[3]/text()')[0] children = html.xpath('//div[@class="team-e"]/p[4]/text()')[0] house = html.xpath('//div[@class="team-e"]/p[5]/text()')[0] add = html.xpath('//div[@class="team-e"]/p[6]/text()')[0] ask_for = html.xpath('//div[@class="hunyin-1-2"]/p[2]/span/text()')[0] document = Document() document.add_heading('甜蜜蜜婚介') document.add_paragraph("姓名:" + name) document.add_paragraph(edu) document.add_paragraph(profession) document.add_paragraph(sponsa) document.add_paragraph(children) document.add_paragraph(house) document.add_paragraph(add) document.add_paragraph(ask_for) document.add_picture("1.jpg") document.add_paragraph(" ") document.save(name + '.docx') url = "https://www.csflhjw.com/team/show.php?id=22" get_data(url)