关于#python批处理#的问题
我有很多txt文件,里面的内容各不相同(储存的都是英文单词,单词之间用逗号分隔),但所有文件都含有一个我不想要的单词(比如assignment),用python怎么实现批量把这个单词去掉……
文本文件,实则就是一个字符串。如果您不想要的不多,用字符串方法 str.replace('不要的单词', '') 就可以了。
原理:把字符串替换为 '' 空字符,本质就是去除了字符串。例如——
代码运行效果截屏图片

Python 代码
#!sur/bin/nve python
# coding: utf-8
s = 'I am a small man.'
print(f"\n{s}\n去除句中的“small”:{s.replace('small', '')}\n")
批处理,用 for 遍历文件名列表即可。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/177164
- 这篇博客你也可以参考下:python读取txt文件,并取每行特定几个位置数据,写到新的文本
- 除此之外, 这篇博客: 使用Python读取数据集的图片路径,划分训练集与验证集并保存到txt文件中中的 6. 测试部分 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
该程序在相对三级目录下进行测试,将存相对路径式为:数据集名称/类别名称/图片 项目目录结构如图所示:
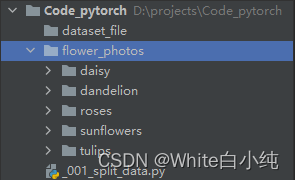
测试代码:
if __name__ == '__main__': # 创建dataset.txt数据集,将flower_photos修改为自己的数据集名称 dataset_path = r'flower_photos' dataset_txt_path = r'dataset_file/dataset.txt' write_dataset2txt(dataset_path, dataset_txt_path) # 划分训练集、验证集与测试集 img_list = get_image_path(dataset_txt_path) # 读取dataset.txt中的内容获得图片路径 train_rate = 0.6 # 训练集比重60% val_rate = 0.2 # 验证集比重20%,测试集比重20% train_path = r'dataset_file/train.txt' val_path = r'dataset_file/val.txt' test_path = r'dataset_file/test.txt' write_train_val_test_list(img_list, train_rate, val_rate, train_path, val_path, test_path) # 获取训练集和验证集图片路径与标签 train_img_path, train_labels, val_img_path, val_labels, classes = get_train_and_val(train_path, val_path) print(f'Total of training images: {len(train_img_path)}') print(f'Total of val images: {len(val_img_path)}') print(f'classes: {classes}')代码运行后的控制台结果:
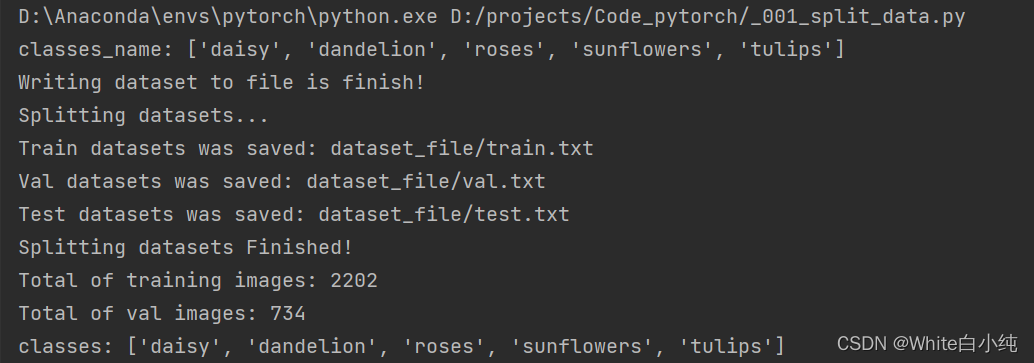
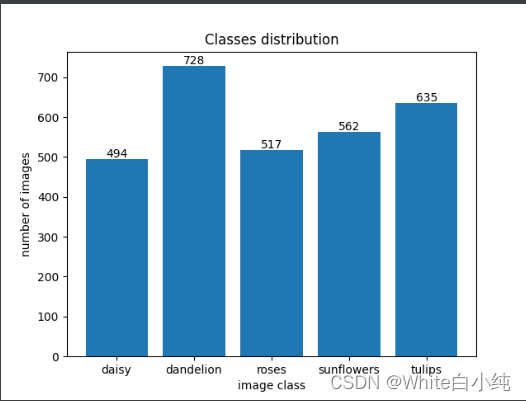
且绘制每个种类参与训练的样本数
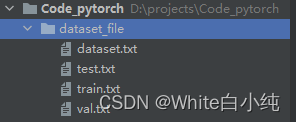
同时,项目中多了4个.txt文件,如图所示
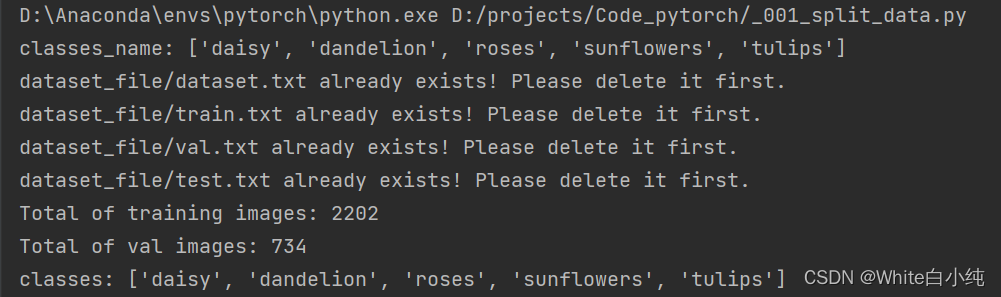
若上述四个文件已存在,再次运行程序,不会执行写入操作,且控制台会打印提醒(如下图),需手动删除上述4个文件,才能执行
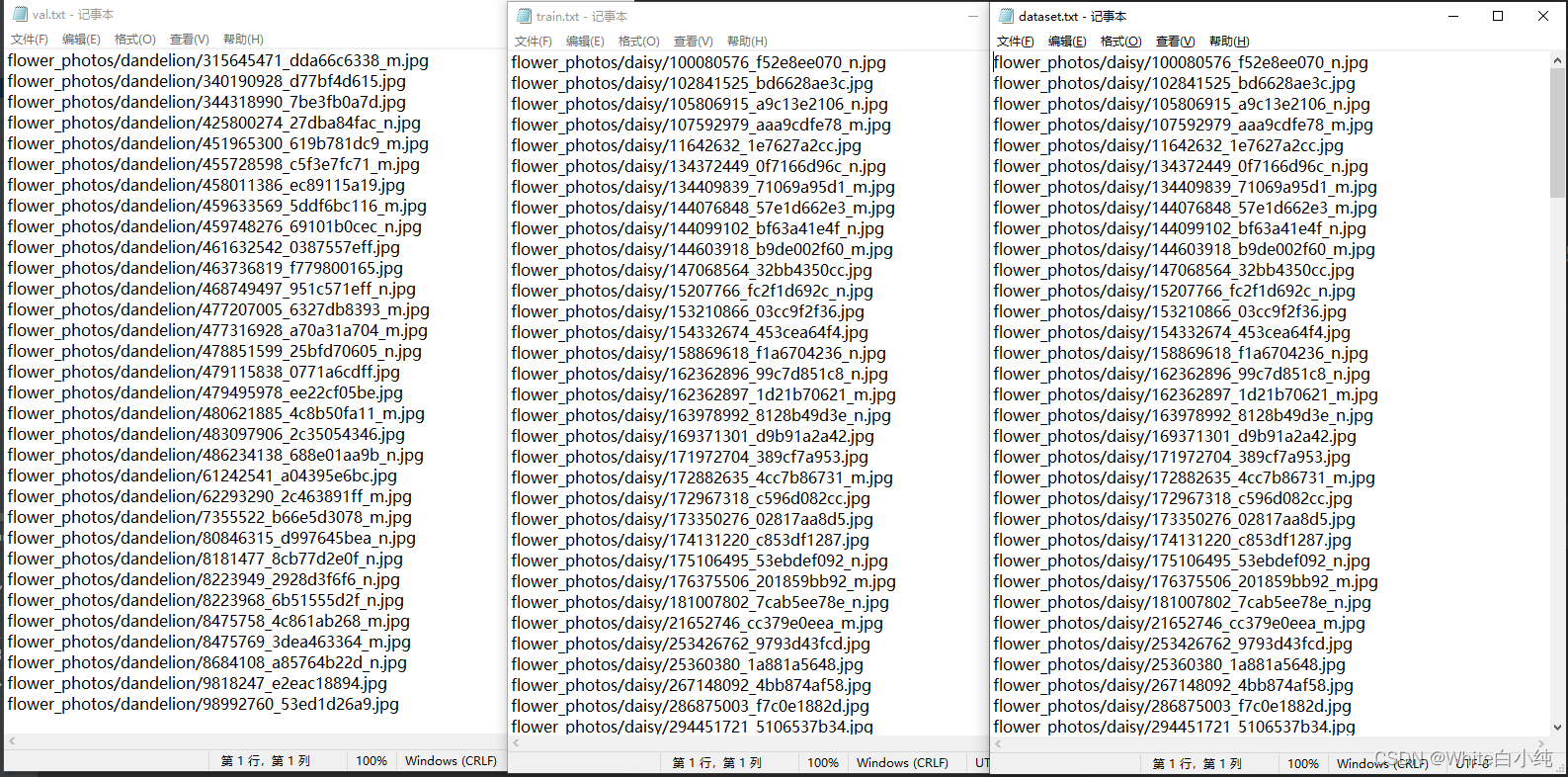
三个文件的部分内容展示如下图,可以看出该程序成果将图片的相对路径存储到txt文件中。
- 您还可以看一下 裴帅帅老师的Python入门编程100例课程中的 Python实现批量Txt文件的合并小节, 巩固相关知识点