RuntimeError: CUDA error: device-side assert triggered
在用deeplabv3+训练自己的模型时,碰到以下报错,但是在训练时,并没有其他的程序在用cuda,只有这一个。请问这个如何解决
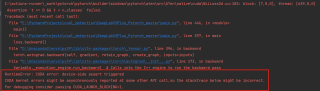
先看下你的显存够不够,如果占比到了90%左右的话,你的显存是可能会不够的情况也会出现这个问题。
另外,从报错的第二行来看,你的这个类别有点问题,就是标签文件里面又class_id大于或者等于num_class的情况,下标从0开始的话,你的clas id最大应该只能取到num_class-1,如果取到值大于这个,也就是出现了越界情况报错。
- 这篇博客: ubunt18.04 搭建模型DeepLab v3+中的 二、安装CUDA 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
1、下载CUDA
https://developer.nvidia.com/cuda-toolkit
如下图选择合适的版本:

cuda_11.0.3_450.51.06_linux.run
2、下载过程中遇到的问题
如下图所示,快下载结束的时候,提示“s段核心已转储”。

解决办法:
使用如下命令进行查看;
ulimit -a可以看到stack size 大小只有8192,太小了
使用如下命令,将stack size 改为100m,问题解决。
ulimit -s 102400参考链接:https://blog.csdn.net/seaflyren/article/details/104131269
3、安装
sudo sh cuda_xx.run(1)Abort与continue,选择continue
(2)图1中按回车键去掉Driver前面的X;选中options,进入图2界面,选中Driver Options,进入图3界面,前3项前面回车选X;图3界面选择Done,进入图2界面,选择Done,进入图1界面,选择Install,等待。
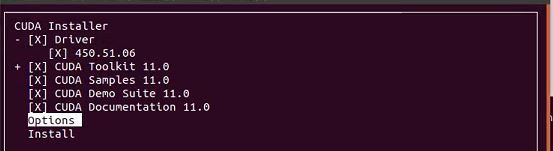
图1
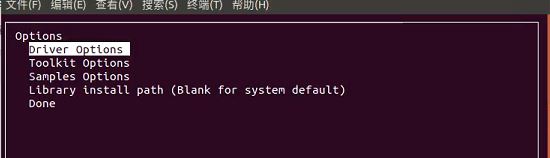
图2

图3
https://blog.csdn.net/RealCoder/article/details/107722616
https://blog.csdn.net/RealCoder/article/details/107722616
5、查看cuda是否安装成功
使用下面命令查看
nvcc -V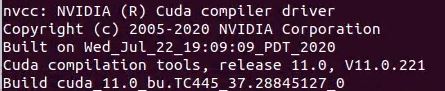
但是在测试cuda的Samples时,出现问题。测试步骤如下:
cd /usr/local/cuda‐11.0/samples/1_Utilities/deviceQuery sudo make ./deviceQuery错误提示:
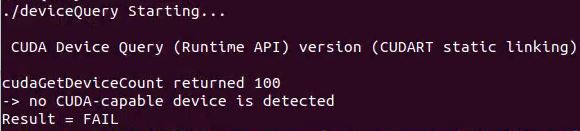
经查找,发现是英伟达驱动存在问题,使用
nvidia-smi错误提示:

解决办法:
参考链接:https://blog.csdn.net/hangzuxi8764/article/details/86572093

再次测试cuda的Samples时,成功

- 以下回答由chatgpt基于相关博客总结生成:
对于深度学习模型中的CUDA错误“RuntimeError: CUDA error: device-side assert triggered”,常见的原因是代码中存在错误或模型的输入数据存在问题。因此可以尝试以下几种解决方案:
1.检查代码中是否存在错误,特别是模型的输入数据是否正确。可以尝试使用一组简单的数据对模型进行测试,以确保模型能够正常运行。可以打印出中间结果,查看运行过程中是否存在异常情况出现,例如出现了无限大或无限小的值。
2.更新显卡驱动程序。可以通过以下步骤来更新驱动程序:
$ sudo add-apt-repository ppa:graphics-drivers $ sudo apt-sudo apt-get update $ sudo apt-get install nvidia-driver-440
在安装完驱动程序后,确认CUDA环境变量的设置是否正确:
$ echo $PATH $ echo $LD_LIBRARY_PATH
3.升级CUDA版本。可以从官方网站下载与显卡相对应的CUDA版本,然后安装并设置环境变量。下面是升级CUDA的简单步骤:
$ sudo apt-get purge nvidia* $ sudo apt-get autoremove $ sudo apt-get install nvidia-driver-440 $ wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/cuda-10-2_10.2.89-1_amd64.deb $ sudo dpkg -i cuda-10-2_10.2.89-1_amd64.deb $ echo 'export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}' >> ~/.bashrc $ echo 'export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc $ source ~/.bashrc
4.降低模型的batch size。有时候内存不足会导致CUDA错误,可以通过减少batch size的大小来解决这个问题。在训练模型前,可以逐渐减小batch size的大小,找到模型可以正常运行的最小batch size。
如果上述方法都不能解决问题,可以在stackoverflow等开发者社区上尝试寻求帮助,也可以考虑更换硬件设备。