scrapy爬虫处理xpath
就是因为pro_Name后面的数字变动导致机型缺失,这个问题我描述不出来找解决方案都找不到。求一个问题描述或者解决方案plz


该回答引用chatgpt:
pro_Name是固定的吗,如果是可以通过正则匹配
pattern = r'^pro_Name' # 匹配以"pro_Name"开头的正则表达式模式
- 这篇博客: 如何使用scrapy爬虫框架(从一无所知到才高八斗)中的 至此,运行startspider.py后,打开数据库,查询即可看到已经采集下来的数据(如果在不报错的情况下,刷新数据库没看到相关数据,可能是你的xpath表达式书写的有问题,须进行debug查看,看data=[ ]中是否有数据,如果为空,则说明xpath表达式有问题) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
下图是本文章最终采集的数据结果(并进行了按评分排序操作):
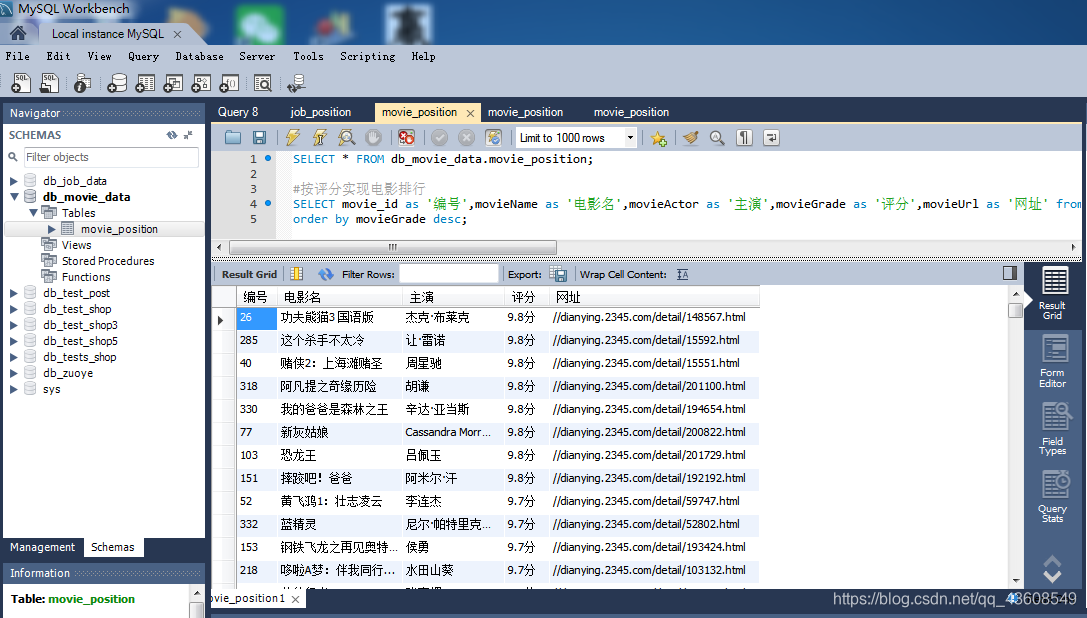
美好的时光总是短暂,不拼尽全力,怎能享受沧海桑田!!!