python检查程序错误
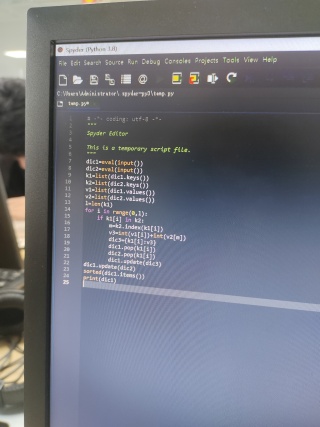
找一下我的程序错在哪了,运行不通过,我觉得应该是我输出的字典中有空格的原因。应该如何修改
写得太麻烦了,直接遍历dic2,在dic1不存在加入到dic1中,否则累加就行,然后对字典items排序下,判断键值是字符串还是数字组合下内容输出
dic1=eval(input())
dic2=eval(input())
for k,v in dic2.items():
if k in dic1:
dic1[k]=dic1[k]+v
else:
dic1[k]=v
items=sorted(dic1.items(),key=lambda x:x[0],reverse=True)
if isinstance(items[0][0],int):##键为数字
items=list(map(lambda x:f"{x[0]}:{x[1]}",items))
else:##键为字典
items=list(map(lambda x:f"'{x[0]}':{x[1]}",items))
print("{"+",".join(items)+"}")
1.直接遍历dic1和dic2,不要搞什么k1,k2,v1,v2
2.要求你倒序排,你哪句代码要求倒序排了
3.sorted函数有返回值,不改变原dict,你自己不先运行一下看看自己的代码到底输出什么吗
dic1.pop那一句删除掉,因为你的for循环是通过事先取的len来循环,中间你有pop掉一些数据,那必然会越界。
把代码贴一下吧。看不清。
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7800853
- 这篇博客也不错, 你可以看下python爬虫,请教一下为何我爬取数据有的完整有的不完整 爬的百家号 登陆这一块还没解决 但关注这一块很难解决
- 同时,你还可以查看手册:python- 错误输出重定向和程序终止 中的内容
- 除此之外, 这篇博客: 我通过Python对自己的微信朋友圈进行了可视化分析得到了意想不到的答案中的 最后了,重磅来袭,输出所有朋友圈的头像合成在一张图片上 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
先看下效果图,当然了,我打马赛克了,不然认识的人看见,发现是我写的,那我就准备new一个自己来了。开玩笑,哈哈。
具体实现完整代码如下:import itchat import os import math from PIL import Image # 获取数据 def download_image(): # 扫描二维码登陆微信,即通过网页版微信登陆 itchat.auto_login() # 返回一个包含用户信息字典的列表 friends = itchat.get_friends(update=True) # 在当前位置创建一个用于存储头像的目录wechatImages base_path = 'wechatImages' if not os.path.exists(base_path): os.mkdir(base_path) # 获取所有好友头像 for friend in friends: # 获取头像数据 img_data = itchat.get_head_img(userName = friend['UserName']) #判断备注名是否为空 if friend['RemarkName'] != '': img_name = friend['RemarkName'] else : img_name = friend['NickName'] # 在实际操作中如果文件名中含有*标志,会报错。则直接可以将其替换掉 if img_name is "*": img_name = "" #通过os.path.join()函数来拼接文件名 img_file = os.path.join(base_path, img_name + '.jpg') print(img_file) with open(img_file, 'wb') as file: file.write(img_data) # 拼接头像 def join_image(): base_path = 'wechatImages' files = os.listdir(base_path) #返回指定的文件或文件夹的名字列表 print(len(files)) each_size = int(math.sqrt(float(6400 * 6400) / len(files)))#计算每个粘贴图片的边长 lines = int(6400 / each_size)#计算总共有多少行 print(lines) image = Image.new('RGB', (6400, 6400))# new(mode, size, color=0) 定义一张大小为640*640大小的图片,不给出第三个参数默认为黑色 x = 0 #定义横坐标 y = 0 #定义纵坐标 for file_name in files: img = Image.open(os.path.join(base_path, file_name)) #找到/打开图片 img = img.resize((each_size, each_size), Image.ANTIALIAS)#实现图片同比例缩放,Image.ANTIALIAS添加滤镜效果 image.paste(img, (x * each_size, y * each_size))#将缩放后的照片放到对应的坐标下 x += 1 if x == lines:#如果每行的粘贴内容够了,则换行 x = 0 y += 1 image.save('jointPic.jpg')#最后将全部的照片保存下来 if __name__ == '__main__': # download_image() join_image()写到这本片就完了,我的头发还是那么茂密!

- 您还可以看一下 程序员学院老师的Python数据分析与挖掘从零开始到实战课程中的 对数据进行分类汇总小节, 巩固相关知识点