在hive中如何将下面字段变成可以做正常排序的数字类型
在hive中如何将下面字段变成可以做正常正序排序的int类型?
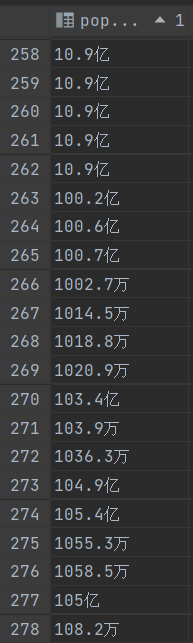
根据你提供的信息,你的字段中的数值有单位,那么解决方法就是对单位进行换算,将万的单位换算为亿之后再进行排序,sql语句如下:
SELECT id, (
case when locate('万', price )>0
THEN CAST(REGEXP_REPLACE(price, '万', '') AS DOUBLE)/10000
ELSE CAST(REGEXP_REPLACE(price, '亿', '') AS DOUBLE)
END
) as price from table_test order by price
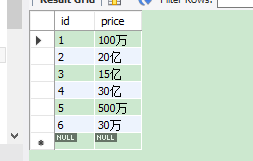
原始测试数据:
经过sql语句的处理和排序之后:
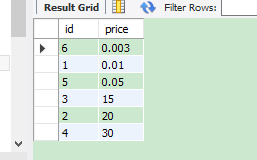
说明sql语句正确。望采纳!!1
- 你可以看下这个问题的回答https://ask.csdn.net/questions/934492
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Hive笔记 —— 表加载数据的六种方式(实例代码,存储文件,数据格式)
- 除此之外, 这篇博客: 大数据项目《网站用户行为分析》综合实验记录中的 对数据仓库Hive中的数据进行查询分析 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
完成了MySQL、Hadoop和Hive三者的启动
就进入了“hive>”命令提示符状态,可以输入类似SQL语句的HiveQL语句。
在“hive>”命令提示符状态下执行下面命令:hive> use dblab; //使用dblab数据库 hive> show tables; //显示数据库中所有表。 hive> show create table bigdata_user; //查看bigdata_user表的各种属性; hive> select behavior_type from bigdata_user limit 10;//查看前10位用户对商品的行为 hive> select visit_date,item_category from bigdata_user limit 20;//查询前20位用户购买商品时的时间和商品的种类查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
hive> select e.bh, e.it from (select behavior_type as bh, item_category as it from bigdata_user) as e limit 20;这里简单的做个讲解,behavior_type as bh ,item_category as it就是把behavior_type 设置别名 bh ,item_category 设置别名 it,FROM的括号里的内容我们也设置了别名e,这样调用时用e.bh,e.it,可以简化代码。
(1)用聚合函数count()计算出表内有多少条行数据
hive> select count(*) from bigdata_user;//用聚合函数count()计算出表内有多少条行数据(2)在函数内部加上distinct,查出uid不重复的数据有多少条
下面继续执行操作:hive> select count(distinct uid) from bigdata_user;//在函数内部加上distinct,查出uid不重复的数据有多少条(3)查询不重复的数据有多少条(为了排除客户刷单情况) **
hive>select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from bigdata_user group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;注意:嵌套语句最好取别名,就是上面的a,否则很容易出现如下错误.
1.以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。(1)查询2014年12月10日到2014年12月13日有多少人浏览了商品
hive>select count(*) from bigdata_user where behavior_type='1' and visit_date<'2014-12-13' and visit_date>'2014-12-10';(2)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
hive> select count(distinct uid), day(visit_date) from bigdata_user where behavior_type='4' group by day(visit_date);2.关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定地点,求当天发出到该地点的货物的数量hive> select count(*) from bigdata_user where province='江西' and visit_date='2014-12-12' and behavior_type='4';1.查询一件商品在某天的购买比例或浏览比例
hive> select count(*) from bigdata_user where visit_date='2014-12-11'and behavior_type='4';//查询有多少用户在2014-12-11购买了商品 hive hive> select count(*) from bigdata_user where visit_date ='2014-12-11';//查询有多少用户在2014-12-11点击了该店根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率。
2.查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)hive> select count(*) from bigdata_user where uid=10001082 and visit_date='2014-12-12';//查询用户10001082在2014-12-12点击网站的次数 hive> select count(*) from bigdata_user where visit_date='2014-12-12';//查询所有用户在这一天点击该网站的次数上面两条语句的结果相除,就得到了要要求的比例。
3.给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户idhive> select uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;//查询某一天在该网站购买商品超过5次的用户id某个地区的用户当天浏览网站的次数
hive> create table scan(province STRING,scan INT) COMMENT 'This is the search of bigdataday' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;//创建新的数据表进行存储 hive> insert overwrite table scan select province,count(behavior_type) from bigdata_user where behavior_type='1' group by province;//导入数据 hive> select * from scan;//显示结果- 您还可以看一下 赵强老师老师的赵强老师:大数据从入门到精通(8)Hive课程中的 数据分析引擎和Hive简介小节, 巩固相关知识点
以下内容部分参考ChatGPT模型:
可以使用hive内置函数cast将该字段转换成int类型,例如:
SELECT CAST(column_name AS INT) FROM table_name;
其中,column_name是需要转换的字段名,table_name是需要操作的表名。
如果我的建议对您有帮助、请点击采纳、祝您生活愉快
给你点思路,全部换成整数。
写个case when
先截取最后一位,作为判断,若等于万 ,结果乘以10000
若等于亿,结果乘以100000000,在排序