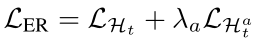有监督学习损失的代码
有监督学损失的代码以及原理什么的有没有指路呀,看了好几篇弄进去loss都是nan
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7763484
- 这篇博客你也可以参考下:【机器学习技巧】-训练过程中,loss参数出现NAN怎么解决?解决方案汇总?
- 除此之外, 这篇博客: 基于模型结构增扩的增量学习方法 归纳和详解中的 2.3 模型结构与loss设计 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:

每新来一个增量任务t
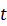 ,就新训练一个特征提取网络Ft
,就新训练一个特征提取网络Ft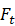 和分类器Hta
和分类器Hta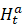 ,然后并入上一个特征提取网络中作为新的特征提取网络。其中,Mask Parameter即前文提及的Channel-Level Mask-Based Pruning Strategy,对特征进行采样,从而降低特征维度,减少存储和运算负担。
,然后并入上一个特征提取网络中作为新的特征提取网络。其中,Mask Parameter即前文提及的Channel-Level Mask-Based Pruning Strategy,对特征进行采样,从而降低特征维度,减少存储和运算负担。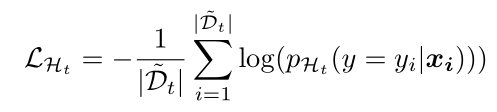
训练loss即交叉熵,用于对整个分类器进行训练(这里的分类器Ht
 相当于原始分类器Ht
相当于原始分类器Ht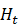 和新增分类器Hta
和新增分类器Hta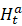 的合并),其中D
的合并),其中D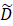 是训练样本与memory中样本的并集。
是训练样本与memory中样本的并集。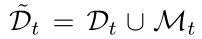
除此自外,作者引入了LHta
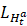 辅助loss,只对分类器的新增部分Hta
辅助loss,只对分类器的新增部分Hta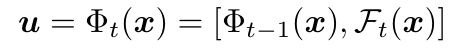 进行训练,
进行训练,