怎么样才可以提升自己的编程能力
听课都能听懂 很多代码也能看得懂 但是一到自己编程就不会 该怎么办啊
看博主博客的码龄不足一年,所以我按大一新生的情况分析:
对编程语法不熟练,一个简单直接的方法:把C++课本所有的代码敲一遍,我以前大一也是刚接触啥也不懂,没怎么接触电脑,所以直接用最笨但页有用的方法,把所有知识点的代码敲一遍。
对算法能力不足的情况,推荐网站:牛客网、leetcode刷题网站,每天哪怕练习一道题,一学期下来也是有进步的!
对编程技术栈不足的情况,推荐网站:哔哩哔哩,这里面几乎包含计算机编程学习所有的网课,真的就是你想学习什么就有什么网课。不用去大学慕课。
注意锻炼,养成良好的生活习惯。学好编程是一战长时间的战役,好的生活习惯可以让你更有效的学习!
希君采纳!感谢
多练。课上教的代码可以自己手打一遍,另外可以找几个oj网站刷题,也可以试着解决自己感兴趣的问题。
先练习简单的,再试着独立解决复杂的问题,把大的问题拆解成小问题。
把可复用的写成函数。注意归纳。要追求代码的效率和简洁。
不停的练习,实践,没有捷径,对于自己感兴趣的,都动手实践下,不要眼高手低,有兴趣可以看下我的一些专栏,或许会有帮助
学习编程语言和学习编程是两回事。并不一定需要学会全部的编程语言的语法才能写程序,好比认字多不等于你能写出好的小说。
可惜学校里面的老师教的是前者。
感觉能看懂和真看懂了之间还隔着好远呢
我看火影的时候,看他们结手印,还感觉自己看懂了呢,到自己结的时候一个都结不出来
所谓外行看热闹,内行看门道
你像看热闹一样的看,怎么看感觉怎么懂
什么时候你能把细节都看明白,能看到代码哪里有错误,哪里写的啰嗦了还可以优化,那才是真看懂了
关键就是你不能老是只看不做
没有人光靠看能学会游泳骑自行车和打篮球
我目前是一个大一的学生,我认为写题的时候要将题目打开来看,要按一步一步的按照逻辑顺序思考题目,然后再用代码敲出来,思考的环节非常非常重要,就用最简单的交换两个数字来说,可以想到生活中的甲乙两杯水的交换,先要找一个丙空杯子 ,再把甲杯中水倒入丙,再把乙倒入甲,再将丙倒入甲,这样就完成了,两数交换亦是如此。初学者没有解题思路是非常正常的,我刚开始学也是一头雾水,没有思路的题可以去搜搜答案 ,但是重点还是要看解题思路,看看别人是怎么想的,和你自己的想法差在哪儿了,要做对比,看还有那些地方没想到,做过的题也不要丢掉,闲了回头看一眼也会对学习有所帮助。
- 你看下这篇博客吧, 应该有用👉 :单片机之间通过串口通信传输数据的传输帧协议设计思路及多字节数据与浮点数的发送接收方法
- 除此之外, 这篇博客: 算法与数据结构之带头结点和不带头结点单链表存在的问题中的 带头结点和不带头结点单链表注意的小细节 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
在写不带头结点的单链表中发现了一个问题,这个问题在带头结点的单链表中也存在,那就是值传递的问题。
首先来看一下#include<stdio.h> #include<malloc.h> #include<stdlib.h> #define Destroy Clear //Destroy和Clear操作是一样的 //和设头结点的单链表在定义存储结构上是相同的 typedef struct Node { int data; //数据域 struct Node *next; //指针域 }NODE,*PNODE; PNODE Create2() { //在表尾插入数据 int i,n; PNODE pHead=NULL,pNew,pTail; printf("请输入数据元素的个数:"); scanf("%d",&n); if(n<1) exit(-1); pHead=(PNODE)malloc(sizeof(NODE));//生成一个首结点 if(NULL==pHead) exit(-1); printf("请输入第1个元素的值:"); scanf("%d",&pHead->data); pHead->next=NULL; pTail=pHead; for(i=0;i<n-1;i++) { pNew=(PNODE)malloc(sizeof(NODE)); if(NULL==pNew) exit(-1); printf("请输入第%d个元素的值:",i+2); scanf("%d",&pNew->data); pNew->next=pTail->next; pTail->next=pNew; pTail=pNew; } return pHead; } void Clear(PNODE pHead) { PNODE p=pHead; while(p!=NULL) { p=pHead->next; free(pHead); pHead=p; } } void Traverse(PNODE pHead) { PNODE p=pHead; while(p!=NULL) { printf("%d ",p->data); p=p->next; } printf("\n"); } int main() { PNODE pHead=Create2(); printf("初始化后元素:"); Traverse(pHead); printf("销毁链表后:\n"); Clear(pHead); Traverse(pHead); return 0; }这是从不带头结点的单链表源码中提取的一段代码,以下是程序运行结果
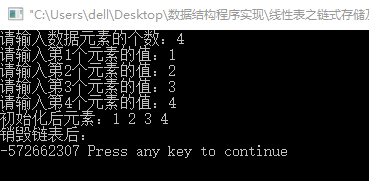
为什么在程序最后会出现-572662307这样的乱码呢?而为什么在前一篇数据结构之带头结点的单链表中最后在销毁链表之后,并且遍历链表元素之后没有出现乱码呢?
首先来看一下从上一篇提取问题代码之后的代码#include<stdio.h> #include<malloc.h> #include<stdlib.h> typedef struct Node { int data; struct Node *next; }NODE,*PNODE; PNODE Create2() { int i,n; PNODE pHead,pTail,pNew; pHead=(PNODE)malloc(sizeof(NODE)); if(NULL==pHead) exit(-1); pHead->next=NULL; //生成头结点 pTail=pHead; printf("请输入数据元素的个数:"); scanf("%d",&n); for(i=0;i<n;i++) { pNew=(PNODE)malloc(sizeof(NODE)); if(NULL==pNew) exit(-1); printf("请输入第%d个元素的值:",i+1); scanf("%d",&pNew->data); pTail->next=pNew; pTail=pTail->next; pNew->next=NULL; } return pHead; } void Destroy(PNODE pHead) { //销毁pHead指向的单链表:头结点也不存在只剩一个头指针,且头指针为NULL PNODE p; while(pHead!=NULL) { p=pHead->next; free(pHead); pHead=p; } } void Traverse(PNODE pHead) { PNODE p=pHead->next; while(p!=NULL) { printf("%d ",p->data); p=p->next; } printf("\n"); } int main() { PNODE pHead=Create2(); printf("初始化后的元素:"); Traverse(pHead); Destroy(pHead); printf("销毁单链表后:"); Traverse(pHead); return 0; }代码运行之后:
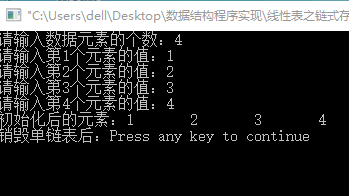
通过观察比较,表面的问题出现在Traverse()这个函数上,
而两个Traverse的区别是:在带头结点的单链表中先执行p=pHead->next;然后判断p是否为空在输出p->data;
而在不带头结点的单链表中先执行p=pHead;然后判断p是否为空在输出p->data;
两者差别就在于不带头结点的输出的是pHead->data;带头结点输出的是pHead->next->data;
下面来分析一下这个问题产生的原因: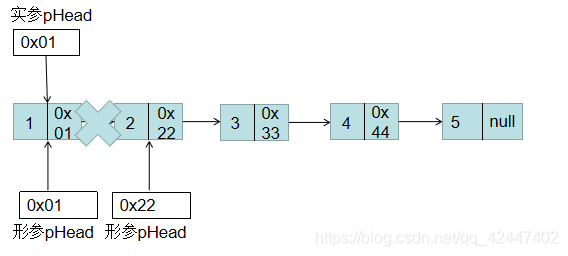 注意:上图为执行不带头结点的Clear函数或Destroy函数,带头结点的Destroy函数执行图只不过就在第一个节点前添加一个头节点,但导致的问题都是相同的。
注意:上图为执行不带头结点的Clear函数或Destroy函数,带头结点的Destroy函数执行图只不过就在第一个节点前添加一个头节点,但导致的问题都是相同的。
首先,在Clear函数时,传递的实参是pHead,形参也是pHead,这样就相当于值传递,让实参和形参都指向相同的元素,但是销毁链表时,是形参的pHead在执行,当释放第一个节点后,形参pHead指向下一个元素,但实参由于指向第一个结点,并且已被释放,所以此时实参pHead内容为乱码,不再是0x01,但是在遍历的时候,不带头结点的会先判断pHead是否为空,因为其中为乱码所以不为空,所以会输出pHead->data为乱码,pHead指向它的下一个结点,检测到下一个结点为空,跳出while循环,所以执行结果会看到乱码,而在带头结点的在进行循环前pHead已经指向它的下一个结点,也就是说它的下一个结点已经为空,所以不会执行while循环,直接结束,也就不会看到乱码现象。这种问题该如何修改呢?
以下提供了两种解决方法(以不带头结点的单链表为例)
第一种:用C语言方式
具体代码如下:void Clear(PNODE *pHead) { PNODE p=*pHead; while(p!=NULL) { p=(*pHead)->next; free(*pHead); *pHead=p; } } int main() { PNODE pHead=Create2(); printf("初始化后元素:"); Traverse(pHead); printf("销毁链表后:\n"); Clear(&pHead); Traverse(pHead); return 0; }对以上两个函数进行修改即可
下面给出修改后的函数执行图: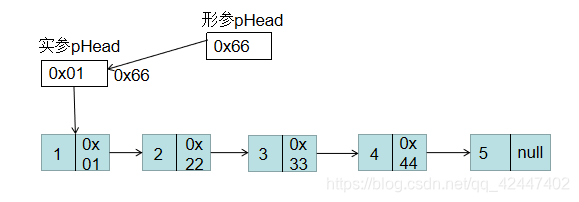
当释放第一个节点后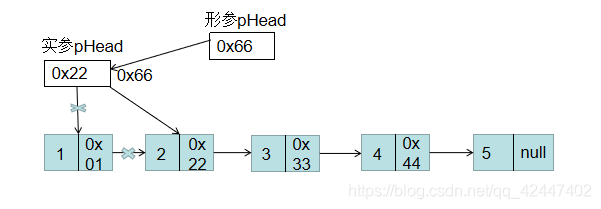 注意:形参pHead存储的是实参pHead变量本身的地址,而通过在函数里使用*pHead意义就是代表形参pHead的内容,也就是实参pHead,由此可以看出修改前后的区别就是,修改前是通过形参来操作函数的销毁,实参不动。而修改过后通过形参控制实参,由实参来操作函数的销毁。由此可以看出两者的本质区别
注意:形参pHead存储的是实参pHead变量本身的地址,而通过在函数里使用*pHead意义就是代表形参pHead的内容,也就是实参pHead,由此可以看出修改前后的区别就是,修改前是通过形参来操作函数的销毁,实参不动。而修改过后通过形参控制实参,由实参来操作函数的销毁。由此可以看出两者的本质区别
第二种:用c++引用实现void Clear(PNODE &pHead) { PNODE p=pHead; while(p!=NULL) { p=pHead->next; free(pHead); pHead=p; } } int main() { PNODE pHead=Create2(); printf("初始化后元素:"); Traverse(pHead); printf("销毁链表后:\n"); Clear(pHead); Traverse(pHead); return 0; }在原始错误的基础上只需要将Clear函数的形参改为(PNODE &pHead)即可。
另外一个值得注意的是在对不带头结点的单链表进行插入和删除操作时传递参数必须是以上的两种方式(如果不采用传递参数方式,也可以采用返回头指针的方式,如创建链表),这也是和带头结点单链表在插入和删除操作上的重要区别- 您还可以看一下 韦语洋(Lccee)老师的一机一码加密、被破解自动销毁随时授权回收升级系列视频课程课程中的 演示如何破解一个软件绕过注册机(仅作为后续课程的了解)小节, 巩固相关知识点
熟能生巧