使用模拟退火粒子群算法时,适应函数无法执行赋值,因为左侧的索引与右侧的大小不兼容
之前也写过一个相对简单点的适应函数,能成功被优化算法调用,但这次写的出现了“无法执行赋值,因为左侧的索引与右侧的大小不兼容”的报错,看了半天也没发现哪里出问题了,求大家解答,急,有偿~
适应函数如下,有很长一部分的调用数据,有些数据在另外的文件里,就不做展示,赋值部分应该没问题。出错的可能在循环部分,里面有6个从优化算法里调用的参数,分别为x(1)到x(6):
function F=fitness(x)
%% 赋值部分
dt=0.001;
R0=3.7454e-4;
L0=9.9351e-5;
Ee1=0;Ee2=0;
ep=0;eq=0;
dUdc=zeros(1000,1);
i_d_ref=zeros(1000,1);
di_d=zeros(1000,1);
U_d_ref=zeros(1000,1);
P_c=zeros(1001,1);
Q_c=zeros(1001,1);
e_p=zeros(1001,1);
e_q=zeros(1001,1);
Udc_in= evalin('base' , 'Udc' );
Udc_ref_in= evalin('base' , 'Udc_ref' );
U_d_in= evalin('base' , 'U_d' );
i_d_in= evalin('base' , 'i_d' );
i_q_in= evalin('base' , 'i_q' );
dUt_in= evalin('base' , 'dUt' );
Ut_ref_in= evalin('base' , 'Ut_ref' );
w0_in= evalin('base' , 'w0' );
P_m= evalin('base' , 'Pt' );
Q_m= evalin('base' , 'Qa' );
%% 循环部分
for i=1:1000
if dUt_in(i,1)< 0.1*Ut_ref_in
i_q_in(i+1,1)=0;
else
i_q_in(i+1,1)= x(5)*dUt_in(i,1);
end
dUdc(i,1) = Udc_ref_in - Udc_in(i,1);
i_d_ref(i,1)= x(1)*dUdc(i,1)+ x(2)*Ee1;
Ee1=Ee1+dUdc(i,1);
di_d(i,1)=i_d_ref(i,1)-i_d_in(i,1);
U_d_ref(i,1)= x(3)*di_d(i,1)+ x(4)*Ee2;
Ee2=Ee2+di_d(i,1);
i_d_in(i+1,1)=i_d_in(i,1)+dt*(U_d_ref(i,1)-U_d_in(i,1)+L0*w0_in(i,1).*i_q_in(i,1)-R0*i_d_in(i,1))/L0;
Udc_in(i+1,1)=Udc_in(i,1)+dt*(566.53-3*U_d_in(i,1).*i_d_in(i,1)/2/Udc_in(i,1))/x(6);
end
for i=1:1001
P_c(i:1)=3*U_d_in(i:1).*i_d_in(i:1)/2;
Q_c(i:1)=3*U_d_in(i:1).*i_q_in(i:1)/2;
e_p(i:1)=(P_m(i:1)-P_c(i:1))^2/1001;
e_q(i:1)=(Q_m(i:1)-Q_c(i:1))^2/1001;
ep=ep+e_p(i:1);
eq=eq+e_q(i:1);
end
%% 优化目标
F=ep+eq;
end
模拟退火粒子群算法是从书上找到的,程序应该没问题,如下:
function [xm,fv]=SimuAPSO(fitness,N,c1,c2,lamda,M,D)
%待优化的目标函数:fitness
%粒子数目:N
%学习因子1:c1
%学习因子2:c2
%退火常数:lamda
%最大迭代次数:M
%自变量的个数:D
%目标函数取最小值时的自变量值:xm
%目标函数的最小值:fv
format long;
for i=1:N
for j=1:D
x(i,j)=randn;
v(i,j)=randn; %随机初始化位置
end
end
for i=1:N
p(i)=fitness(x(i,:)); %**报错的位置 **
y(i,:)=x(i,:);
end
pg=x(N,:); %Pg为全局最优
for i=1:(N-1)
if fitness(x(i,:))pg=x(i,:);
end
end
T=fitness(pg)/log(5); %初始温度
for t=1:M
groupFit=fitness(pg);
for i=1:N %当前温度下各个Pi的适应值
Tfit(i)=exp(-(p(i)-groupFit)/T);
end
SumTfit=sum(Tfit);
Tfit=Tfit/SumTfit;
pBet=rand();
for i=1:N %用轮盘赌策略确定全局最优的某个替代值
ComFit(i)=sum(Tfit(1:i));
if pBet<=ComFit(i)
pg_plus=x(i,:);
break
end
end
C=c1+c2;
ksi=2/abs(2-C-sqrt(C^2-4*C)); %速度压缩因子
for i=1:N
v(i,:)=ksi*(v(i,:)+c1*rand*(y(i,:)-x(i,:))+c2*rand*(pg_plus-x(i,:)));
x(i,:)=x(i,:)+v(i,:);
if fitness(x(i,:))if p(i)pg=y(i,:);
end
end
T=T*lamda; %退温操作
end
xm=pg';
fv=fitness(pg);
最后通过下面语句进行目标优化:
[xm,fv]=SimuAPSO(@fitness,100,2.05,2.05,0.5,1000,6);
%[xm,fv]=SimuAPSO(@fitness, N, c1, c2, lamda, M, D)
%待优化的目标函数:fitness
%粒子数目:N
%学习因子1:c1
%学习因子2:c2
%退火常数:lamda
%最大迭代次数:M
%自变量的个数:D
%目标函数取最小值时的自变量值:xm
%目标函数的最小值:fv
结果就是如标题一样的报错,报错的图如下:
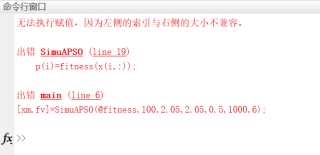
优化的适应函数中参数有6个,最后调用语句也是设置的D=6进行参数个数的设置,可能问题出在适应函数里面,但我确实不太清楚问题在哪,求大手子帮助~
1、检查赋值操作 2、检查变量大小
然后有几个小错误
for i=1:1001
P_c(i:1)=3*U_d_in(i:1).*i_d_in(i:1)/2;
Q_c(i:1)=3*U_d_in(i:1).*i_q_in(i:1)/2;
e_p(i:1)=(P_m(i:1)-P_c(i:1))^2/1001;
e_q(i:1)=(Q_m(i:1)-Q_c(i:1))^2/1001;
ep=ep+e_p(i:1);
eq=eq+e_q(i:1);
end
在就是你用了索引“i:1”,会导致大小不匹配
for i=1:1001
P_c(i)=3*U_d_in(i).*i_d_in(i)/2;
Q_c(i)=3*U_d_in(i).*i_q_in(i)/2;
e_p(i)=(P_m(i)-P_c(i))^2/1001;
e_q(i)=(Q_m(i)-Q_c(i))^2/1001;
ep=ep+e_p(i);
eq=eq+e_q(i);
end
在循环部分的赋值语句中,有两个地方出现了数组索引的问题。
第一个出错的地方是:
P_c(i:1)=3*U_d_in(i:1).*i_d_in(i:1)/2;
Q_c(i:1)=3*U_d_in(i:1).*i_q_in(i:1)/2;
e_p(i:1)=(P_m(i:1)-P_c(i:1))^2/1001;
e_q(i:1)=(Q_m(i:1)-Q_c(i:1))^2/1001;
这里应该把“:1”改成“:”,即:
P_c(i,:)=3*U_d_in(i,:).*i_d_in(i,:)/2;
Q_c(i,:)=3*U_d_in(i,:).*i_q_in(i,:)/2;
e_p(i,:)=(P_m(i,:)-P_c(i,:)).^2/1001;
e_q(i,:)=(Q_m(i,:)-Q_c(i,:)).^2/1001;
第二个出错的地方是:
ep=ep+e_p(i:1);
eq=eq+e_q(i:1);
这里应该把“:1”改成“:”,即:
ep=ep+e_p(i,:);
eq=eq+e_q(i,:);
请尝试修改以上代码,看看是否能够消除错误。
确实是第二部分的循环写错了,一直没注意
- 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:手撕自动驾驶算法——传感器融合算法:卡尔曼滤波器和扩展卡尔曼滤波器
- 除此之外, 这篇博客: 文字机器人,从0到1中的 机器人已经进入大家的视野,现在无论是到商场管家,有些大型商场已经有机器人做引路,还是给你打电话卖保险、卖房子的各种销售电话,都有可能是机器人,而不是真人,知识通过声音,现在已经可以做到让你分不清是真人还是机器人,科技进度,如此之大,最近在研究文字机器人,已经在企业层面上得到应用,可以看下他的组成部分。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:

由于是NLP能力,那么可以做的事情就非常的多,我主要讲下分词、实体抽取、词向量的一些基础知识,

上面是一个比较通用的流程,一个对话请求进来后,首先进行意图识别(关键字、相似问、词向量等),槽位实体解析,然后看下命中哪些个标准问,也就是意图已经识别到后,看下进行策略优化,看进入多轮还是单轮,然后根据回复管理进行意图返回。
中文分词:Python中分分词工具很多,包括盘古分词、Yaha分词、Jieba分词、清华THULAC等,大同小异,我们使用的是jieba分词,为什么使用jieba只要是他的ES插件比较方便,但也不是主要选择他的原因,我们分词还是依靠积累起来的特殊词库和行业词库,我们大概积累了800W多万个,基本解决了冷启动的问题
jieba分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。我们主要用到了1、3,主要是用来做语义分析,和查找标准问,也就是所谓的意图。
实体抽取:我们把他分为几个类似,枚举、正则、关键字抽取,在另一篇文章中,我会着重写我们如何构建多轮会话系统的建模过程,实体抽取的问题在于如何快和准,之前参加过腾讯具备的机器人交流会,他们也是既有规划式,然后通过L2R进行在归总:

词向量:做词向量的算法很多,词向量经典模型:从word2vec、glove、ELMo到BERT,词向量对分词的准确性要求和语料要求很高,语料我们使用了很多家公司合起来的语料进行训练,也有试过腾讯实验室公布的词向量模型,如果在特殊行业,还是需要对语料进行积累,不然冷启动是个很大的问题,这里我就不一一讲解各个算法了,外面对这些算法的文章实在太多,搜一下一大把,不过后续我还是会逐一根据我自己的理解去写一些东西,帮助大家理解。
意图识别:个人认为是现在公共解决方案比较弱的一个环节,如何做好词向量、搜索引擎的得分、关键词的得分,然后进行组装,需要根据场景对这几个比重进行调节,比较繁琐