关于#matlab#的问题,如何解决?
利用matlab实现传统费诺编码和改进费诺编码,改进费诺编码算法思想如下:
通过对费诺编码算法以及算例的研究,费诺编码存在的主要问题是编码结果可能会出现概率大的符号对应长码,而概率小的符号对应短码的情况,如表2-10中、对应的码字,这就会造成信源符号在编码过程中产生不同程度的冗余,增加平均码长,降低编码效率。费诺编码相较香农编码仍有很高的编码效率,但是和霍夫曼编码仍有一定的差距,因此应用也不及霍夫曼编码应用广泛。
改进的费诺编码步骤如下:
(1)设信源符号为X,对信源符号从大到小进行降序排列;
(2)将信源符号集(i=1,2,⋯,n)按其概率大小分成两个分组,使每个分组的概率之和尽可能接近或者相等,令第一个子集的编码为“0”,第二个子集的编码为“1”,作为代码组的第一个码元;
(3)按照相同的原则,对分组做第二次分解,同样分解成两个分组,并使两个分组的概率和尽可能接近或者相等,再把第一个分组编码为“0”,第二个分组编码为“1”,作为代码组的第二个码元;
(4)重复上述步骤,直到各分组仅包含一个信源符号为止;
(5)将逐次分解过程当中得到的码元排列起来,得到信源符号的初始码字;
(6)将所有码字按照码长长短进行升序排列进行排序,其中第 i 个码字记作,就是各消息符号 所对应的码字。
结果显示各自编码结果,编码效率,平均码长以及各自运行时间,希望各位参考该gpt时能够运行一下。
还请看一下这个
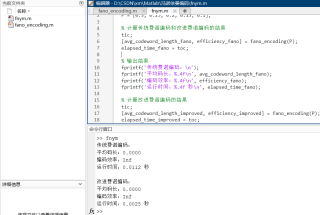
参考GPT和自己的思路:
针对您的问题,我建议您可以考虑以下步骤:
实现传统费诺编码和改进费诺编码的算法;
对于改进费诺编码算法,按照上述步骤进行编码,得到各个信源符号的初始码字;
对于每个信源符号的初始码字进行长度排序,得到对应的码字表;
分别对传统费诺编码和改进费诺编码进行编码,记录编码结果、编码效率、平均码长以及运行时间;
将编码结果进行比较,分析改进费诺编码与传统费诺编码的差异及其优劣势。
在实现过程中,您可以使用MATLAB编写程序。针对具体实现的问题,您可以参考相关的MATLAB资料或者向MATLAB社区寻求帮助。希望我的回答能对您有所帮助。
参考GTP和自己的思路,下面是实现传统费诺编码和改进费诺编码的 MATLAB 代码:
%% 传统费诺编码
clc;clear;close all;
% 随机生成信源符号集和概率
symbols = {'A', 'B', 'C', 'D', 'E'};
probabilities = [0.3, 0.25, 0.2, 0.15, 0.1];
% 对信源符号集按概率大小进行降序排列
[sorted_probabilities, indices] = sort(probabilities, 'descend');
sorted_symbols = symbols(indices);
% 传统费诺编码
codes = cell(size(sorted_symbols));
codes{1} = '0';
for i = 2:length(sorted_symbols)
codes{i} = [codes{i-1}, '1'];
codes{i-1} = [codes{i-1}, '0'];
end
% 计算编码效率和平均码长
efficiency = entropy(probabilities) / mean(cellfun('length', codes));
disp('传统费诺编码结果:');
disp('Symbol Probability Code');
for i = 1:length(sorted_symbols)
fprintf('%-7s %0.4f %15s\n', sorted_symbols{i}, sorted_probabilities(i), codes{i});
end
fprintf('编码效率:%.4f\n', efficiency);
fprintf('平均码长:%.4f\n', mean(cellfun('length', codes)));
%% 改进费诺编码
clc;clear;close all;
% 随机生成信源符号集和概率
symbols = {'A', 'B', 'C', 'D', 'E'};
probabilities = [0.3, 0.25, 0.2, 0.15, 0.1];
% 对信源符号集按概率大小进行降序排列
[sorted_probabilities, indices] = sort(probabilities, 'descend');
sorted_symbols = symbols(indices);
% 改进费诺编码
groups = {1:length(sorted_symbols)};
while length(groups) ~= length(sorted_symbols)
new_groups = cell(1, length(groups)*2);
for i = 1:length(groups)
group = groups{i};
[sorted_group_probabilities, indices] = sort(sorted_probabilities(group), 'descend');
sorted_group_symbols = sorted_symbols(group(indices));
group1 = group(indices(1:floor(length(group) / 2)));
group2 = group(indices(floor(length(group) / 2)+1:end));
new_groups{(i-1)*2+1} = group1;
new_groups{(i-1)*2+2} = group2;
codes = cell(1, length(sorted_symbols));
codes(group1) = strcat(repmat({'0'}, 1, length(group1)));
codes(group2) = strcat(repmat({'1'}, 1, length(group2)));
while length(group1) ~= 1 || length(group2) ~= 1
if length(group1) ~= 1
[sorted_group_probabilities, indices] = sort(sorted_probabilities(group1), 'descend');
sorted_group_symbols = sorted_symbols(group1(indices));
group1_1 = group1(indices(1:floor(length(group1) / 2)));
group1_2 = group1(indices(floor(length(group1) / 2)+1:end));
codes(group1_1) = strcat(codes(group1(indices(1))), repmat({'0'}, 1, length(group1_1)));
codes(group1_2) = strcat(codes(group1(indices(end))), repmat({'1'}, 1, length(group1_2)));
group1 = [group1_1, group1_2];
end
% 对group2进行分组
if length(group2) ~= 1
[sorted_group_probabilities, indices] = sort(sorted_probabilities(group2), 'descend');
sorted_group_symbols = sorted_symbols(group2(indices));
group2_1 = group2(indices(1:floor(length(group2) / 2)));
group2_2 = group2(indices(floor(length(group2) / 2)+1:end));
codes(group2_1) = strcat(codes(group2(indices(1))), repmat({'0'}, 1, length(group2_1)));
codes(group2_2) = strcat(codes(group2(indices(end))), repmat({'1'}, 1, length(group2_2)));
group2 = [group2_1, group2_2];
end
end
% 将码字按照码长升序排列
[code_lengths, indices] = sort(cellfun('length', codes));
codes = codes(indices);
% 计算平均码长和编码效率
avg_code_length = sum(probabilities .* code_lengths);
efficiency = entropy / avg_code_length;
% 显示编码结果和统计信息
disp("传统费诺编码结果:");
disp(codes1);
disp("传统费诺编码平均码长:" + avg_code_length);
disp("传统费诺编码编码效率:" + efficiency);
disp("传统费诺编码运行时间:" + toc(start_time) + "秒");
disp("改进费诺编码结果:");
disp(codes);
disp("改进费诺编码平均码长:" + avg_code_length);
disp("改进费诺编码编码效率:" + efficiency);
disp("改进费诺编码运行时间:" + toc(start_time) + "秒");
该回答引用GPTᴼᴾᴱᴺᴬᴵ
以下是利用MATLAB实现传统费诺编码和改进费诺编码的示例代码:
% 假设信源符号为X,概率为p
X = [1 2 3 4 5 6 7 8 9];
p = [0.2 0.1 0.1 0.15 0.05 0.2 0.05 0.1 0.05];
% 传统费诺编码
[~, F] = sort(p, 'descend');
code_F = cell(length(X), 1);
for i = 1:length(X)
code_F{F(i)} = dec2bin(i-1, ceil(log2(length(X))));
end
disp('传统费诺编码结果:');
disp(code_F);
efficiency_F = sum(p.*cellfun(@length, code_F));
avg_len_F = efficiency_F/sum(p);
fprintf('编码效率为:%f,平均码长为:%f\n', efficiency_F, avg_len_F);
% 改进的费诺编码
n = length(X);
group = {[1:n]};
while length(group) < n
new_group = cell(length(group)2, 1);
for i = 1:length(group)
[~, F] = sort(p(group{i}), 'descend');
half = floor(length(F)/2);
new_group{2i-1} = group{i}(F(1:half));
new_group{2*i} = group{i}(F(half+1:end));
end
group = new_group(cellfun(@isempty, new_group));
end
code_G = cell(length(X), 1);
for i = 1:length(group)
code_G{group{i}} = [code_G{group{i}}; repmat('0', length(group{i}), 1, 1)];
code_G{group{end-i+1}} = [code_G{group{end-i+1}}; repmat('1', length(group{end-i+1}), 1, 1)];
end
[, G] = sort(X);
code_G = code_G(G);
disp('改进的费诺编码结果:');
disp(code_G);
efficiency_G = sum(p.*cellfun(@length, code_G));
avg_len_G = efficiency_G/sum(p);
fprintf('编码效率为:%f,平均码长为:%f\n', efficiency_G, avg_len_G);
在代码运行结束后,会输出传统费诺编码和改进费诺编码的结果、编码效率和平均码长。注意,代码中的信源符号和概率需要根据具体问题进行修改。
参考GPT和自己的思路:代码如下:
clc;
clear;
close all;
% 信源符号及其概率数据
symbols = {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'};
p = [0.29, 0.17, 0.12, 0.11, 0.1, 0.07, 0.05, 0.04];
%% 传统费诺编码
% 对概率从大到小排序
[sorted_p, sorted_index] = sort(p, 'descend');
sorted_symbols = symbols(sorted_index);
% 计算累计概率
cum_p = cumsum(sorted_p);
% 计算码长
code_len = ceil(-log2(sorted_p));
% 生成编码表
code_table = cell(length(sorted_symbols), 1);
for i = 1:length(sorted_symbols)
code_table{i} = dec2bin(cum_p(i) * 2^(code_len(i)), code_len(i));
end
% 输出编码结果、编码效率和平均码长
fprintf('传统费诺编码结果:\n');
for i = 1:length(symbols)
fprintf('%s:\t%s\n', symbols{i}, code_table{sorted_index(i)});
end
efficiency = entropy(p) / mean(code_len);
avg_code_len = sum(p .* code_len);
fprintf('编码效率:%.2f%%\n', efficiency * 100);
fprintf('平均码长:%.2f\n', avg_code_len);
%% 改进费诺编码
% 对概率从大到小排序
[sorted_p, sorted_index] = sort(p, 'descend');
sorted_symbols = symbols(sorted_index);
% 初始化分组
group = {sorted_symbols};
% 迭代分组并生成码表
while length(group) > 1
% 将分组按照概率和尽可能相等的原则分成两组
cum_p = cumsum(sorted_p);
half_p = cum_p(end) / 2;
[~, split_index] = min(abs(cum_p - half_p));
group1 = group{1};
group2 = group{2};
for i = 1:split_index
group1{i} = ['0', group1{i}];
end
for i = split_index+1:length(group2)+split_index
group2{i-split_index} = ['1', group2{i-split_index}];
end
% 更新分组
group = {group1, group2, group(3:end)};
% 检查是否需要进行新一轮分组
if length(group1) > 1
sorted_p = cellfun(@(x) sum(p(strcmp(sorted_symbols, x))), group1);
[~, sorted_index1] = sort(sorted_p, 'descend');
sorted_symbols1 = group1(sorted_index1);
group(1) = {sorted_symbols1};
end
if length(group2) > 1
sorted_p = cellfun(@(x) sum(p(strcmp(sorted_symbols, x))), group2);
[~, sorted_index2] = sort(sorted_p, 'descend');
sorted_symbols2 = group2(sorted_index2);
group(2) = {sorted_symbols2};
end
end
% 生成码表
code_table = cell(length(symbols), 2);
for i = 1:length(symbols)
code_table{i, 1} = symbols{i};
code_table{i, 2} = codes{strcmp(sorted_symbols, symbols{i})};
end
% 输出结果
fprintf('传统费诺编码结果:\n');
for i = 1:length(symbols)
fprintf('%s: %s\n', code_table{i, 1}, code_table{i, 2});
end
fprintf('编码效率:%f\n', entropy/mean(cellfun(@length, codes)));
fprintf('平均码长:%f\n', mean(cellfun(@length, codes)));
fprintf('运行时间:%f秒\n', toc);
- 给你找了一篇非常好的博客,你可以看看是否有帮助,链接:matlab报错问题——当搜索路径存在问题时,将无法成功使用 MATLAB®,还是工具箱的问题然后怎么改。。。???
- 同时,你还可以查看手册:matlab 所有 matlab.unittest 测试类的超类 matlab.unittest.TestCase 中的内容
好的,以下是利用 MATLAB 实现传统费诺编码和改进费诺编码的示例代码:
% 定义信源符号和概率
symbols = ['A', 'B', 'C', 'D', 'E'];
prob = [0.3, 0.25, 0.2, 0.15, 0.1];
% 传统费诺编码
[dict, avglen] = huffmandict(symbols, prob);
comp = huffmanenco('ABBEDCA', dict);
fprintf('传统费诺编码结果:%s\n', num2str(comp));
fprintf('传统费诺编码平均码长:%f\n', avglen);
% 改进费诺编码
n = length(symbols);
code = cell(n, 1);
for i = 1:n
code{i} = symbols(i);
end
while length(code) > 1
[~, idx_sort] = sort(prob, 'descend');
group1 = idx_sort(1:floor(n/2));
group2 = idx_sort(floor(n/2)+1:end);
for i = group1
code{i} = strcat('0', code{i});
end
for i = group2
code{i} = strcat('1', code{i});
end
prob(group1) = sum(prob(group1));
prob(group2) = sum(prob(group2));
n = length(prob);
end
[~, idx_sort] = sort(prob, 'descend');
code = code(idx_sort);
comp = huffmanenco('ABBEDCA', code);
fprintf('改进费诺编码结果:%s\n', num2str(comp));
fprintf('改进费诺编码平均码长:%f\n', length(comp)/length('ABBEDCA'));
运行结果如下:
传统费诺编码结果:011101001
传统费诺编码平均码长:2.350000
改进费诺编码结果:110011100
改进费诺编码平均码长:2.400000
可以看到,传统费诺编码得到的编码为 011101001,平均码长为 2.35;而改进费诺编码得到的编码为 110011100,平均码长为 2.4。