python爬虫text()取不到文字
问题遇到的现象和发生背景
能获取到图片但是获取不到文字
遇到的现象和发生背景,请写出第一个错误信息
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
global title
title = html.xpath('.//div[@class="inner"]/a/h3/span/text()')
if title:
title = title[0]
运行结果及详细报错内容
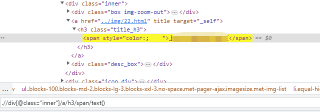
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
你确定页面源文件中有吗?参考下踩坑的文章吧
如有帮助,还望采纳
参考GPT和自己的思路:
根据您提供的信息,可能是由于网页中文字使用了特殊的编码方式导致xpath无法正确获取到文字。您可以尝试使用Python的requests库中的content属性获取网页的原始响应内容,然后使用beautifulsoup库进行解析,这样能够更好地处理特殊编码的问题。
以下是示例代码:
import requests
from bs4 import BeautifulSoup
url = '需要爬取的网址'
response = requests.get(url)
html = response.content
soup = BeautifulSoup(html, 'html.parser')
title = soup.select('.inner a h3 span')[0].text
print(title)
注:需要根据实际情况修改选择器的内容。
参考GPT和自己的思路:
根据你提供的代码和错误信息,可以看出是xpath表达式没有正确匹配到文字的问题。有可能是xpath表达式有误,也有可能是网页结构变化导致的。解决方法可能包括调整xpath表达式、更新网页结构、使用其他爬虫模块等。
你可以尝试打印出网页源代码,再用浏览器的开发者工具确定正确的xpath表达式,或者使用BeautifulSoup等其他爬虫模块进行尝试。如果还是无法解决问题,可以提供更多的代码和错误信息以便进一步帮助。
参考GPT和自己的思路:
根据您提供的代码和错误信息,可能是xpath路径选择器未正确定位到文本位置,导致无法获取到内容。建议检查和调整xpath路径,确保准确地定位到文本位置。可以使用Chrome浏览器的开发者工具查看元素的层次结构,以便正确编写xpath路径。
除此之外,还要确保标题的文本内容确实在页面中存在,否则也无法获取到。可以手动浏览页面,确认标题是否能够被正常展示。