求“京东用户行为数据分析”数据
python+SQL实战:京东用户行为数据分析案例
文章数据来源京东JDATA竞赛,求一份数据
求数据
我用百度网盘链接分享给你:需要你自己下载
链接:https://pan.baidu.com/s/1V2qNurHiN4oV0auwVVgUNg
提取码:94dx
小魔女参考了bing和GPT部分内容调写:
京东用户行为数据分析是一个非常重要的研究课题,它可以帮助我们更好地了解用户的行为习惯,从而更好地满足用户的需求。要获取京东用户行为数据,需要从以下几个方面入手:
从京东官网获取用户行为数据:从京东官网上获取用户行为数据,可以通过爬虫技术来获取用户行为数据,包括用户浏览、购买、评论等行为数据。
从第三方数据源获取用户行为数据:第三方数据源可以提供更丰富的用户行为数据,可以从中获取用户的搜索行为、支付行为、收藏行为等数据。
从用户自身收集用户行为数据:可以通过用户自身收集用户行为数据,比如用户填写的调查问卷、用户反馈的评价等,可以收集到更多的用户行为数据。
使用机器学习技术获取用户行为数据:可以利用机器学习技术,从用户的历史行为数据中提取出用户的行为特征,从而获取用户行为数据。
使用数据挖掘技术获取用户行为数据:可以利用数据挖掘技术,从用户的历史行为数据中提取出用户的行为规律,从而获取用户行为数据。
以上就是获取京东用户行为数据的几种方法,可以根据实际需求,选择合适的方法来获取用户行为数据。
回答不易,记得采纳呀。
“Devil组”引证GPT后的撰写:
- 在京东JDATA竞赛的官方网站上查找相关信息和数据:https://jdata.jd.com/html/detail.html?id=2
- 另外,我可以建议您使用公开可用的数据集进行Python和SQL的实战练习。以下是一些公开可用的数据集:
MovieLens: 电影评分数据集,包含电影评分和用户评分数据。网址:https://grouplens.org/datasets/movielens/
Kaggle: 一个数据科学竞赛平台,提供大量的公开数据集。网址:https://www.kaggle.com/datasets
UCI Machine Learning Repository: 一个公开可用的机器学习数据集库,包含各种类型的数据集。网址:https://archive.ics.uci.edu/ml/index.php
在京东JDATA竞赛的官方网站上查找相关信息和数据:https://jdata.jd.com/html/list.html
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
如果您想要练习“京东用户行为数据分析”的Python+SQL实战,可以前往京东JDATA竞赛官网下载数据集。下面是具体操作步骤。
前往京东JDATA竞赛官网:https://jdata.jd.com/
如果您还没有账号,可以先进行注册,然后登录。
进入“数据下载”页面:https://jdata.jd.com/html/detail.html?id=8
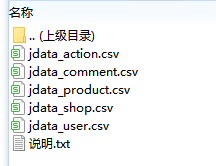
下载数据集:右侧“下载”栏目中,依次下载“jdata_user.csv”、“jdata_product.csv”、“jdata_comment.csv”、“jdata_action.csv”共四个数据集。这些数据分别包含了:
- jdata_user.csv:京东用户数据,包括用户ID、注册时间、用户等级、性别、年龄等信息
- jdata_product.csv:京东商品数据,包括商品ID、品牌ID、品类ID等信息
- jdata_comment.csv:京东评价数据,包括用户ID、商品ID、评价时间、评价星级等信息
- jdata_action.csv:京东用户行为数据,包括用户ID、商品ID、行为时间、行为类型等信息
- 下载完成后,可以利用Python pandas库和SQL语句进行数据清洗、处理和分析。以下是代码示例:
import pandas as pd
from sqlalchemy import create_engine
# 读取数据
user_df = pd.read_csv('jdata_user.csv', encoding='utf-8')
product_df = pd.read_csv('jdata_product.csv', encoding='utf-8')
comment_df = pd.read_csv('jdata_comment.csv', encoding='utf-8')
action_df = pd.read_csv('jdata_action.csv', encoding='utf-8')
# 数据清洗
user_df.drop_duplicates(['user_id'], inplace=True) # 删除重复数据
user_df['user_reg_dt'] = pd.to_datetime(user_df['user_reg_tm'].apply(lambda x: str(x)[:10])) # 转换日期格式
# 数据存储
engine = create_engine('sqlite:///jdata.db')
user_df.to_sql('users', engine, if_exists='replace', index=False)
product_df.to_sql('products', engine, if_exists='replace', index=False)
comment_df.to_sql('comments', engine, if_exists='replace', index=False)
action_df.to_sql('actions', engine, if_exists='replace', index=False)
# SQL查询示例
pd.read_sql_query('''
SELECT a.user_id, COUNT(DISTINCT a.sku_id) AS goods_cnt
FROM actions a
WHERE a.type = 6 AND strftime('%Y-%m-%d', a.time) = '2017-04-15'
GROUP BY a.user_id
ORDER BY goods_cnt DESC
''', engine)
以上代码示例中,我们先通过pandas库读取四个数据集,然后针对用户数据进行了数据清洗,最后将所有数据存储到SQLite数据库中。接着,我们使用SQL查询语句分
不知道你这个问题是否已经解决, 如果还没有解决的话:- 看下这篇博客,也许你就懂了,链接:爬取京东商品并分析
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^