关于#爬虫#的问题:爬虫爬取tr中的td内容,我的代码之前可以爬另一个几乎一样的网页(语言-python)
爬虫爬取tr中的td内容,我的代码之前可以爬另一个几乎一样的网页,不知道为什么这个就不行了
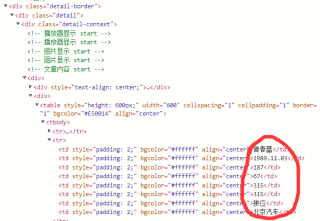
回答:你可以把你的脚本贴一下,这个网页结构还是比较清晰的,可以用beautifulsoup比较容易获取到内容
爬虫爬取tr中的td内容,我的代码之前可以爬另一个几乎一样的网页,不知道为什么这个就不行了
回答:你可以把你的脚本贴一下,这个网页结构还是比较清晰的,可以用beautifulsoup比较容易获取到内容