在 xbert 提供的代码中,为什么 BertLMHeadModel.generate() 方法得到的结果全是相同的?
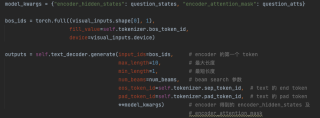
在 xbert 提供的代码中,有一个 BertLMHeadModel 类,我将其作为模型的 text_decoder,希望它能通过 generate() 方法,根据 text_encoder 中得到 encoder_hidden_states 和 encoder_attention_mask 来解码出对应的 text token,输入参数具体如图所示,但是为什么 outputs 输出的每一项都相同?而且在我去除 **model_kwargs 参数的情况下,模型仍能跑出一样的结果(但是在别的模型中,这一参数是必须的)?其中 self.text_decoder 就是 BertLMHeadModel。
该回答引用ChatGPT
输出每一项相同可能是因为在使用 generate() 方法时,没有指定需要生成的文本长度,因此生成的文本长度可能是固定的,或者在默认的情况下,输出长度可能是相同的。你可以在使用 generate() 方法时传递 max_length 和 min_length 参数来指定生成的文本长度的范围,从而得到不同的输出。
至于 model_kwargs 参数,它可以用来传递模型中的其他参数,例如 encoder_hidden_states 和 encoder_attention_mask 等,以便在模型中使用。如果你的模型不需要这些参数,那么你可以忽略这个参数,模型仍然可以正常运行。在你的模型中,如果你没有使用这些参数,那么你可以尝试在调用 generate() 方法时不传递这个参数,以避免混淆。