docker会kill进程吗
背景: docker在运行过程中内存用完了或者说内存长时间占用100%。
问题: docker会继续保持现状,还是会选择kill也就是杀掉部分进程来解除当前状态?如果会kill那如何选择目标进程?
猜测: docker在out of memory的时候会kill掉占用内存最高的进程来恢复到正常状态。
有没有docker大拿回答一下遇到过的情况
- 这篇博客也许可以解决你的问题👉 :Docker 理解进程(1):为什么我在容器中不能kill 1号进程?
- 同时,你还可以查看手册:linux kill 用于手动终止进程。kill命令向一个进程发送信号,终止该进程。 中的内容
- 除此之外, 这篇博客: Docker 理解进程(1):为什么我在容器中不能kill 1号进程?中的 现象解释 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
现在,你应该理解 init 进程和 Linux 信号这两个概念了,让我们回到开头的问题上来:“为什么我在容器中不能 kill 1 号进程,甚至 SIGKILL 信号也不行?”
你还记得么,在课程的最开始,我们已经尝试过用 bash 作为容器 1 号进程,这样是无法把 1 号进程杀掉的。那么我们再一起来看一看,用别的编程语言写的 1 号进程是否也杀不掉。
我们现在用 C 程序作为 init 进程,尝试一下杀掉 1 号进程。和 bash init 进程一样,无论 SIGTERM 信号还是 SIGKILL 信号,在容器里都不能杀死这个 1 号进程。
# cat c-init-nosig.c #include <stdio.h> #include <unistd.h> int main(int argc, char *argv[]) { printf("Process is sleeping\n"); while (1) { sleep(100); } return 0; }# docker stop sig-proc;docker rm sig-proc # docker run --name sig-proc -d registry/sig-proc:v1 /c-init-nosig # docker exec -it sig-proc bash [root@5d3d42a031b1 /]# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 07:48 ? 00:00:00 /c-init-nosig root 6 0 5 07:48 pts/0 00:00:00 bash root 19 6 0 07:48 pts/0 00:00:00 ps -ef [root@5d3d42a031b1 /]# kill 1 [root@5d3d42a031b1 /]# kill -9 1 [root@5d3d42a031b1 /]# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 07:48 ? 00:00:00 /c-init-nosig root 6 0 0 07:48 pts/0 00:00:00 bash root 20 6 0 07:49 pts/0 00:00:00 ps -ef我们是不是这样就可以得出结论——“容器里的 1 号进程,完全忽略了 SIGTERM 和 SIGKILL 信号了”呢?你先别着急,我们再拿其他语言试试。
接下来,我们用 Golang 程序作为 1 号进程,我们再在容器中执行 kill -9 1 和 kill 1 。
这次,我们发现 kill -9 1 这个命令仍然不能杀死 1 号进程,也就是说,SIGKILL 信号和之前的两个测试一样不起作用。
但是,我们执行 kill 1 以后,SIGTERM 这个信号把 init 进程给杀了,容器退出了。
# cat go-init.go package main import ( "fmt" "time" ) func main() { fmt.Println("Start app\n") time.Sleep(time.Duration(100000) * time.Millisecond) }# docker stop sig-proc;docker rm sig-proc # docker run --name sig-proc -d registry/sig-proc:v1 /go-init # docker exec -it sig-proc bash [root@234a23aa597b /]# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 1 08:04 ? 00:00:00 /go-init root 10 0 9 08:04 pts/0 00:00:00 bash root 23 10 0 08:04 pts/0 00:00:00 ps -ef [root@234a23aa597b /]# kill -9 1 [root@234a23aa597b /]# kill 1 [root@234a23aa597b /]# [~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES对于这个测试结果,你是不是反而觉得更加困惑了?
为什么使用不同程序,结果就不一样呢?接下来我们就看看 kill 命令下达之后,Linux 里究竟发生了什么事,我给你系统地梳理一下整个过程。
在我们运行 kill 1 这个命令的时候,希望把 SIGTERM 这个信号发送给 1 号进程,就像下面图里的带箭头虚线。
在 Linux 实现里,kill 命令调用了 kill() 的这个系统调用(所谓系统调用就是内核的调用接口)而进入到了内核函数 sys_kill(), 也就是下图里的实线箭头。
而内核在决定把信号发送给 1 号进程的时候,会调用 sig_task_ignored() 这个函数来做个判断,这个判断有什么用呢?
它会决定内核在哪些情况下会把发送的这个信号给忽略掉。如果信号被忽略了,那么 init 进程就不能收到指令了。
所以,我们想要知道 init 进程为什么收到或者收不到信号,都要去看看 sig_task_ignored() 的这个内核函数的实现。
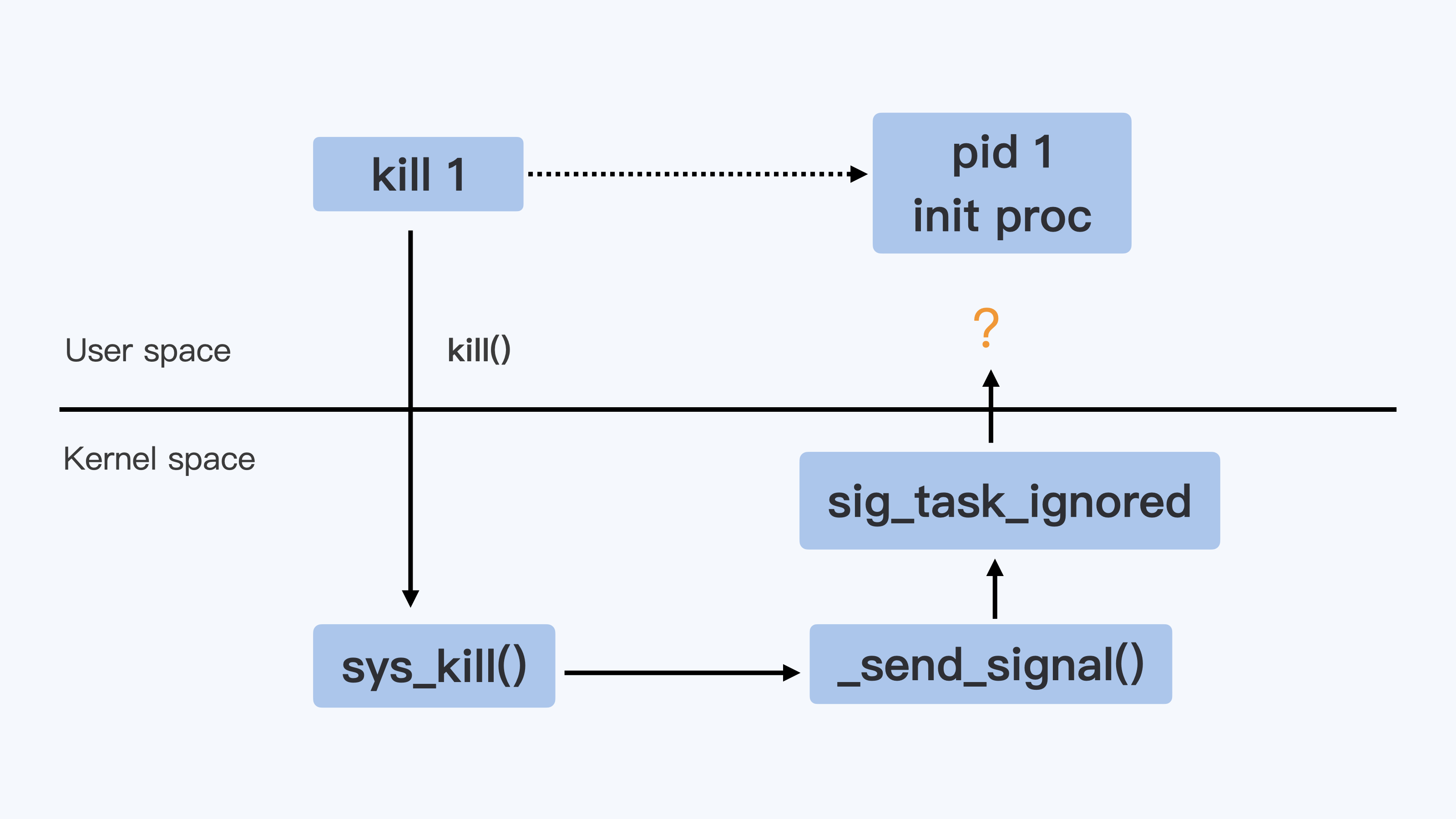
sig_task_ignored()内核函数实现示意图
在 sig_task_ignored() 这个函数中有三个 if{}判断,第一个和第三个 if{}判断和我们的问题没有关系,并且代码有注释,我们就不讨论了。
我们重点来看第二个 if{}。我来给你分析一下,在容器中执行 kill 1 或者 kill -9 1 的时候,这第二个 if{}里的三个子条件是否可以被满足呢?
我们来看下面这串代码,这里表示一旦这三个子条件都被满足,那么这个信号就不会发送给进程。
kernel/signal.c static bool sig_task_ignored(struct task_struct *t, int sig, bool force) { void __user *handler; handler = sig_handler(t, sig); /* SIGKILL and SIGSTOP may not be sent to the global init */ if (unlikely(is_global_init(t) && sig_kernel_only(sig))) return true; if (unlikely(t->signal->flags & SIGNAL_UNKILLABLE) && handler == SIG_DFL && !(force && sig_kernel_only(sig))) return true; /* Only allow kernel generated signals to this kthread */ if (unlikely((t->flags & PF_KTHREAD) && (handler == SIG_KTHREAD_KERNEL) && !force)) return true; return sig_handler_ignored(handler, sig); }接下来,我们就逐一分析一下这三个子条件,我们来说说这个"!(force && sig_kernel_only(sig))" 。
第一个条件里 force 的值,对于同一个 Namespace 里发出的信号来说,调用值是 0,所以这个条件总是满足的。
我们再来看一下第二个条件 “handler == SIG_DFL”,第二个条件判断信号的 handler 是否是 SIG_DFL。
那么什么是 SIG_DFL 呢?对于每个信号,用户进程如果不注册一个自己的 handler,就会有一个系统缺省的 handler,这个缺省的 handler 就叫作 SIG_DFL。
对于 SIGKILL,我们前面介绍过它是特权信号,是不允许被捕获的,所以它的 handler 就一直是 SIG_DFL。这第二个条件对 SIGKILL 来说总是满足的。
最后再来看一下第三个条件,"t->signal->flags & SIGNAL_UNKILLABLE",这里的条件判断是这样的,进程必须是 SIGNAL_UNKILLABLE 的。
这个 SIGNAL_UNKILLABLE flag 是在哪里置位的呢?
可以参考我们下面的这段代码,在每个 Namespace 的 init 进程建立的时候,就会打上 SIGNAL_UNKILLABLE 这个标签,也就是说只要是 1 号进程,就会有这个 flag,这个条件也是满足的。
kernel/fork.c if (is_child_reaper(pid)) { ns_of_pid(pid)->child_reaper = p; p->signal->flags |= SIGNAL_UNKILLABLE; } /* * is_child_reaper returns true if the pid is the init process * of the current namespace. As this one could be checked before * pid_ns->child_reaper is assigned in copy_process, we check * with the pid number. */ static inline bool is_child_reaper(struct pid *pid) { return pid->numbers[pid->level].nr == 1; }我们可以看出来,其实最关键的一点就是 handler == SIG_DFL 。Linux 内核针对每个 Namespace 里的 init 进程,把只有 default handler 的信号都给忽略了。
如果我们自己注册了信号的 handler(应用程序注册信号 handler 被称作"Catch the Signal"),那么这个信号 handler 就不再是 SIG_DFL 。即使是 init 进程在接收到 SIGTERM 之后也是可以退出的。
不过,由于 SIGKILL 是一个特例,因为 SIGKILL 是不允许被注册用户 handler 的(还有一个不允许注册用户 handler 的信号是 SIGSTOP),那么它只有 SIG_DFL handler。
所以 init 进程是永远不能被 SIGKILL 所杀,但是可以被 SIGTERM 杀死。
说到这里,我们该怎么证实这一点呢?我们可以做下面两件事来验证。
第一件事,你可以查看 1 号进程状态中 SigCgt Bitmap。
我们可以看到,在 Golang 程序里,很多信号都注册了自己的 handler,当然也包括了 SIGTERM(15),也就是 bit 15。
而 C 程序里,缺省状态下,一个信号 handler 都没有注册;bash 程序里注册了两个 handler,bit 2 和 bit 17,也就是 SIGINT 和 SIGCHLD,但是没有注册 SIGTERM。
所以,C 程序和 bash 程序里 SIGTERM 的 handler 是 SIG_DFL(系统缺省行为),那么它们就不能被 SIGTERM 所杀。
具体我们可以看一下这段 /proc 系统的进程状态:
### golang init # cat /proc/1/status | grep -i SigCgt SigCgt: fffffffe7fc1feff ### C init # cat /proc/1/status | grep -i SigCgt SigCgt: 0000000000000000 ### bash init # cat /proc/1/status | grep -i SigCgt SigCgt: 0000000000010002第二件事,给 C 程序注册一下 SIGTERM handler,捕获 SIGTERM。
我们调用 signal() 系统调用注册 SIGTERM 的 handler,在 handler 里主动退出,再看看容器中 kill 1 的结果。
这次我们就可以看到,在进程状态的 SigCgt bitmap 里,bit 15 (SIGTERM) 已经置位了。同时,运行 kill 1 也可以把这个 C 程序的 init 进程给杀死了。
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> void sig_handler(int signo) { if (signo == SIGTERM) { printf("received SIGTERM\n"); exit(0); } } int main(int argc, char *argv[]) { signal(SIGTERM, sig_handler); printf("Process is sleeping\n"); while (1) { sleep(100); } return 0; }# docker stop sig-proc;docker rm sig-proc # docker run --name sig-proc -d registry/sig-proc:v1 /c-init-sig # docker exec -it sig-proc bash [root@043f4f717cb5 /]# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 09:05 ? 00:00:00 /c-init-sig root 6 0 18 09:06 pts/0 00:00:00 bash root 19 6 0 09:06 pts/0 00:00:00 ps -ef [root@043f4f717cb5 /]# cat /proc/1/status | grep SigCgt SigCgt: 0000000000004000 [root@043f4f717cb5 /]# kill 1 # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES好了,到这里我们可以确定这两点:
- kill -9 1 在容器中是不工作的,内核阻止了 1 号进程对 SIGKILL 特权信号的响应。
- kill 1 分两种情况,如果 1 号进程没有注册 SIGTERM 的 handler,那么对 SIGTERM 信号也不响应,如果注册了 handler,那么就可以响应 SIGTERM 信号。
是的,docker在内存用完的情况下会选择杀掉占用内存最多的进程,以达到恢复正常状态的目的。但是有时候可能会出现一些异常,导致其他进程被杀掉。所以为了避免出现异常,建议您定期监控docker容器的内存使用状态,以便及时发现问题与时间及时做出调整,从而达到最佳的性能。
以下答案引用自GPT-3大模型,请合理使用:
:
是的,docker会杀掉占用内存最高的进程以节省空间。
要防止docker在内存不足时杀死进程,可以使用docker API中的“memory constraints”功能设置内存限制。例如:
$ docker run --memory 800m <image_name>
上面的命令将启动一个容器,并限制其最大内存限制为800MB,从而避免容器在内存不足时被杀死。
此外,AI 可以使用docker cgroup的memory.force_empty参数来配置docker的行为,比如:
$ docker run --memory-forceempty true <image_name>
这将允许docker强制杀掉占用内存最高的进程来恢复到正常状态。
如果我的回答解决了您的问题,请采纳我的回答