求用python匹配数据段的代码
问题遇到的现象和发生背景
我需要一个python代码,实现从数据库中匹配最相似的数据段。
我输入的数据段与匹配的数据时间长度并不一定相等,之前了解到许多是用DTW的方法来实现。许多案例是计算两个数据之间的相似度,而我需要从一堆数据库中筛选出最为匹配的数据,起点和终点都未知。也许要完成这个功能单凭DTW并不能胜任,就请帮我实现。具体请见示例图:
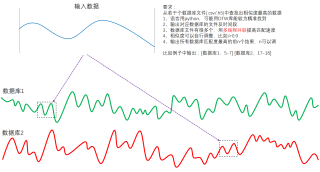
我想要达到的结果
我将一个dataframe里面某个数据输入程序,程序从我的数据库文件夹里匹配出最为相似的数据段并输出时间,只需要告诉是哪个数据文件的哪一段即可。数据库文件夹里要么全部是CSV文件,要么全部是H5,你就当时CSV吧,我可以根据情况自行修改。由于数据库里文件较多,所以希望能提升匹配速度。如果对程序中的个别代码有疑惑,希望可以与你沟通。
多写注释,不要贴图啊,我要直接ctrl C+V 运行,私信我。可以运行我就采纳了。
有兴趣的私信我,我把测试数据发给你,效果好的话我会+200
请根据你的数据存储情况修改应用代码中的路径。如果匹配数据文件较多,建议将debug设置为False
# -*- coding: utf-8 -*-
import os, sys, time
import numpy as np
import pandas as pd
from scipy import interpolate
class CurveMatchPipe:
"""时序数据匹配流水线"""
def __init__(self, sample_file, data_folder, max_var=0.1, debug=False):
"""构造函数
sample_file - 样本数据文件名
data_folder - 数据仓库路径
max_var - 偏离方差(数值越小,曲线越相似)
"""
data_csv = self.read_csv(sample_file)
if data_csv is None:
print('样本数据文件%s缺少time列或aim列,程序终止运行。'%sample_file)
sys.exit(1)
stamp, data = self.data_cleaning(*data_csv, 'linear')
self.sample = (data - data.mean()) / data.std()
self.data_folder = data_folder
self.max_var = max_var
self.debug = debug
self.time_cost = list()
self.result = {
'数据文件': list(),
'起始时间': list(),
'截止时间': list(),
'起始索引': list(),
'截止索引': list(),
'偏离方差': list()
}
def read_csv(self, fn):
"""读取数据文件,返回时间戳数组和aim数组"""
stamp, data = list(), list()
with open(fn, 'r') as fp:
lines = fp.readlines()
col_names = lines[0].split(',')
if 'time' in col_names:
idx_time = col_names.index('time')
else:
return None
if 'aim' in col_names:
idx_aim = col_names.index('aim')
else:
return None
for line in lines[1:]:
items = line.split(',')
stamp.append(int(items[idx_time]))
data.append(float(items[idx_aim]))
return np.array(stamp), np.array(data)
def is_continuous(self, stamp):
"""判断时间戳是否连续"""
return np.where(np.diff(stamp) != 1)[0].shape[0] == 0
def data_cleaning(self, stamp, data, method='linear'):
"""数据清洗。对于缺值数据默认线性插值,可选样条插值(cubic)"""
if self.is_continuous(stamp):
return stamp, data
f = interpolate.interp1d(stamp, data, kind=method)
stamp_new = np.linspace(stamp[0], stamp[-1], stamp[-1]-stamp[0]+1)
data_new = f(stamp_new)
return np.int32(stamp_new), data_new
def match(self):
"""遍历数据仓库,匹配样本数据"""
for fn in os.listdir(self.data_folder):
t0 = time.time()
if self.debug:
print('正在处理文件%s...'%fn, end='')
if os.path.splitext(fn)[1] != '.csv':
if self.debug:
print('忽略:文件格式错误')
continue
data_csv = self.read_csv(os.path.join(self.data_folder, fn))
if data_csv is None:
if self.debug:
print('忽略:缺少time列或aim列')
continue
stamp, data = self.data_cleaning(*data_csv, 'linear')
m, n = self.sample.shape[0], data.shape[0]
d = np.vstack([data[i:n-m+1+i] for i in range(m)]).T
d_mean = d.mean(axis=1).reshape(-1,1)
d_std = d.std(axis=1).reshape(-1,1)
d = (d - d_mean) / d_std
diff = d - self.sample
variance = diff.var(axis=1)
for idx in np.argsort(variance):
if variance[idx] > self.max_var:
break
self.result['数据文件'].append(fn)
self.result['起始时间'].append(stamp[idx])
self.result['截止时间'].append(stamp[idx+m])
self.result['起始索引'].append(idx)
self.result['截止索引'].append(idx+m)
self.result['偏离方差'].append(variance[idx])
if self.debug:
print('完成')
t1 = time.time()
self.time_cost.append(t1-t0)
def report(self, out_file=None):
"""打印DataFrame结构的匹配结果报告,若提供输出文件名,则生成excel文件"""
report = pd.DataFrame(self.result)
n = len(self.time_cost)
total = sum(self.time_cost)
mean = total/n
if out_file:
report.to_excel(out_file, sheet_name='匹配结果')
else:
print('---------------------------------------------------------------------------------')
print(report)
print('---------------------------------------------------------------------------------')
print('共计处理%d个数据文件,累计耗时%.3f秒,单个文件平均用时%.3f秒'%(n, total, mean))
if __name__ == '__main__':
cmp = CurveMatchPipe('data/samples/data.csv', 'data/storehouse', max_var=0.3, debug=True)
cmp.match()
cmp.report('report.xlsx')
提供一下输入数据吧
围观大佬提问,一看就很复杂的亚子呢
总得有个最小时间片吧,
背景信息
我有一个Python脚本,它用docx模块生成word文档。这些文档是根据日志生成的,然后作为记录打印和存储。但是,日志可以追溯编辑,因此需要修订文档记录,并且必须跟踪这些修订。实际上,我并不是在修改文档,而是生成一个新文档,它显示当前日志中的内容与即将在日志中显示的内容之间的差异(打印修订后的文件后更新日志)。当修订发生时,我的脚本使用diff_match_patch来生成一个标记,其中包含以下函数所做的更改:def revFinder(str1,str2):
dmp = dmp_module.diff_match_patch()
diffs = dmp.diff_main(str1,str2)
paratext = []
for diff in diffs:
paratext.append((diff[1], '' if diff[0] == 0 else ('s' if diff[0] == -1 else 'b')))
return paratext
docx可以将文本作为字符串,如果需要逐字格式化,则可以使用元组,因此[请参阅“一些要注意的事项”中的第二个项目]
^{pr2}$
生产Hello my nameis Brad
问题
diff_match_patch是一个非常有效的代码,它可以发现两个文本之间的差异。不幸的是,它有点太高效了,所以用dune替换{}会导致redunante
这很难看,但用一个词就行了。但是,如果整个段落被替换,结果将完全不可读。这不好。在
以前我通过将所有的文本压缩成一个单独的段落来解决这个问题,但是这并不理想,因为它变得非常混乱,而且仍然非常难看。在
目前的解决方案
我有一个创建修订文档的函数。此函数将传递如下设置的元组列表:[(fieldName, original, revised)]
所以文件被设置为Orignial fieldName (With Markup)
result of revFinder diffing orignal and revised
Revised fieldName
revised
我假设为了解决这个问题,我需要在段落之间做一些匹配,以确保我不会区分两个完全独立的段落。我还假设这种匹配将取决于段落是添加还是删除。以下是我目前掌握的代码:if len(item[1].split('\n')) + len(item[1].split('\n'))) == 2:
body.append(heading("Original {} (With Markup)".format(item[0]),2))
body.append(paragraph(revFinder(item[1],item[2])))
body.append(paragraph("",style="BodyTextKeep"))
body.append(heading("Revised {}".format(item[0]),2))
body.append(paragraph(item[2]))
body.append(paragraph(""))
else:
diff = len(item[1].split('\n')) - len(item[1].split('\n'))
if diff == 0:
body.append(heading("Original {} (With Markup)".format(item[0]),2))
for orPara, revPara in zip(item[1].split('\n'),item[2].split('\n')):
body.append(paragraph(revFinder(orPara,revPara)))
body.append(paragraph("",style="BodyTextKeep"))
body.append(heading("Revised {}".format(item[0]),2))
for para in item[2].split('\n'):
body.append(paragraph("{}".format(para)))
body.append(paragraph(""))
elif diff > 0:
#Removed paragraphs
elif diff < 0:
#Added paragraphs
到目前为止,我已经计划使用类似difflib来进行段落匹配。但是如果有更好的方法来避免这个问题,那就是完全不同的方法,那也很好。在
注意事项:我在Windows7 64位上运行32位python2.7.6
我对docx的本地副本进行了一些更改(即添加了删除线格式),因此如果您测试此代码,您将无法复制我在这方面所做的工作
整个过程的描述(修订步骤以粗体显示):
1)用户打开Python脚本并使用GUI向一个称为“条件报告”(CR)的东西添加信息NOTE: A full CR contains 4 parts, all completed by different people. But each part gets individually printed. All 4 parts are
stored together in the log
2)当用户完成后,信息被保存到日志中(如下所述),然后作为.docx文件打印
3)打印文件已签字保存
4)当用户想要修改CR的一部分时,打开GUI,编辑每个字段中的信息。我只关心这个问题中的几个字段,这些字段是多行文本控件(这可能导致多个段落)
5)一旦用户完成了修订,代码就会生成我在“到目前为止的解决方案”部分中描述的元组列表,并将其发送到生成修订文档的函数
6)修订文件与CR该部分的原始文件一起创建、打印、签署和存储
7)日志被完全重写,以包含修订后的信息
日志:
日志只是一个巨大的dict,它存储了所有CRs上的所有信息。一般格式是{"Unique ID Number": [list of CR info]}
日志不存储CR的过去版本,因此当CR被修改时,旧的信息将被覆盖(这就是我们所说的系统的需求)。正如我前面提到的,每次编辑日志时,整个过程都会被重写。为了获取日志中的信息,我import它(因为它总是与脚本位于同一个目录中)
总结一下文本相似度分析的步骤:
1、读取文档
2、对要计算的多篇文档进行分词
3、对文档进行整理成指定格式,方便后续进行计算
4、计算出词语的词频
5、【可选】对词频低的词语进行过滤
6、建立语料库词典
7、加载要对比的文档
8、将要对比的文档通过doc2bow转化为词袋模型
9、对词袋模型进行进一步处理,得到新语料库
10、将新语料库通过tfidfmodel进行处理,得到tfidf
11、通过token2id得到特征数
12、稀疏矩阵相似度,从而建立索引
13、得到最终相似度结果
1,读取文档
2、对要计算的多篇文档进行分词
3、对文档进行整理成指定格式,方便后续进行计算
4、计算出词语的词频
5、对词频低的词语进行过滤
6、建立语料库词典
7、加载要对比的文档
8、将要对比的文档通过doc2bow转化为词袋模型
9、对词袋模型进行进一步处理,得到新语料库
10、将新语料库通过tfidfmodel进行处理,得到tfidf
11、通过token2id得到特征数
12、稀疏矩阵相似度,从而建立索引
13、得到最终相似度结果