大神们,小弟求助一下java正则的截取
现有从.txt读取打印的代码如下:
String fileName ="F:\\py2\\wxprints.txt";
FileReader fileReader = new FileReader(fileName);
BufferedReader bufferedReader = new BufferedReader(fileReader);
System.out.println("字符集:"+fileReader.getEncoding());
String line =bufferedReader.readLine();
while (line!=null){
System.out.println(line);
line = bufferedReader.readLine();
}
打印及记事本的内容如下:
打印部分截图:

记事本整个截图:

小弟想如下图所示截取记事本中内所有的'text':后面的文字,该如何截取?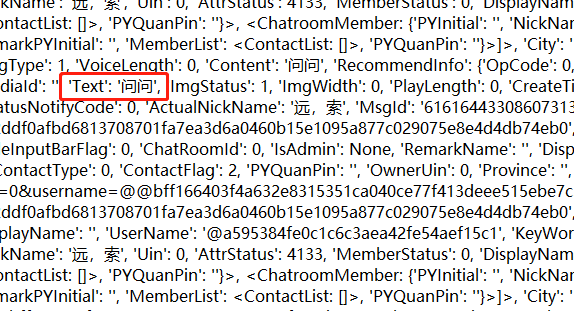
小弟拜谢
首先,正则表达式的作用是匹配,不是截取哟,你这个可能一步到位不了,你要做的是先匹配出带Text的规则,然后用其他字符函数截取,如substring,正则不是用来做截取的呢。
解析为java数组对象,然后取值
简单的正则(?<='Text':')[\s\S]+?(?=',)
看你的截图是单引号,如果是双引号自己替换
上面的正则的意思:查找开头以“'Text':'”结尾以“',”的字符
看这么多水的,直接发代码吧
public static void main(String[] args) {
String st = "dffsf'Text':'2222',sdsf'Text':'111',";
Matcher matcher = Pattern.compile("(?<='Text':')[\s\S]+?(?=',)").matcher(st);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
兄弟 看你的图片截图,是个json字符串啊, 你用JsonObJect把字符串转Json对象 然后取Text的值 不就取到了么 ,不用去正则匹配截取
建议反序列化为object去取值,正则效率不高的。 可以用idea的Gsonformat插件轻松实现, 只要粘贴你要反序列化的json就行。