用Python爬取豆瓣电影链接,为何爬下来的链接总是重复出现两次
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("https://movie.douban.com/")
bsobj = BeautifulSoup(html)
for titles in bsobj.findAll("li",{"class":"title"}):
print(titles.get_text())
for link in bsobj.findAll("a",href = re.compile("https://movie.douban.com/subject/.*/?from=showing")):
if 'href' in link.attrs:
print(link.attrs['href'])
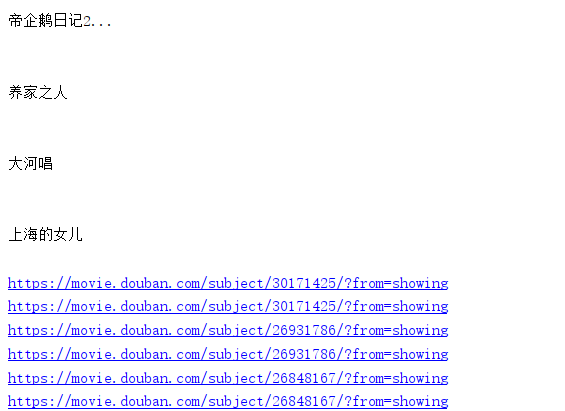
因为图片和标题都有链接,所以加一个条件筛选
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("https://movie.douban.com/")
bsobj = BeautifulSoup(html)
for titles in bsobj.findAll("li",{"class":"title"}):
print(titles.get_text())
for link in bsobj.findAll("a",{"onclick":"moreurl(this, {from:'mv_a_pst'})"},href = re.compile("https://movie.douban.com/subject/.*/?from=showing")):
if 'href' in link.attrs:
print(link.attrs['href'])
这是因为原网页中本来就有两个同样的连接,你可以把找到的连接用一个集合保存,然后再遍历集合,这样可以去重,
或者,你在筛选的时候再精细点