关于python爬虫下载的文件数据丢失无法打开
最近在写一个下载器,下载阿里系某个平台的文件。response.content下载下来的文件只有4,5k;请求头和参数都带上了(抓包),想问下各位有遇到过吗?有什么思路吗?
参数是这个:
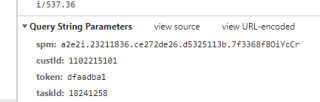
请求头:
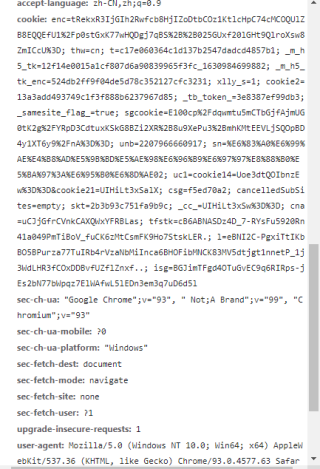
对于请求的文件较大时,使用iter_content,分块获取写入。关于Iter_content的作用查看其函数说明。不能保证可正确获取,但是作为一个思路你可以尝试一下。
import requests
res=requests.get(url,headers={'User-Agent':'Mozilla/5.0'},data=data,stream=True)
for chunk in res.iter_content(chunk_size=1024):
with open('a.zip','wb') as f:
f.write(chunk)



文件网址,但是要登陆才能下载的······
好像是用get······我再试试······
还有一个问题,某些下载文件的连接,在浏览器上打开的时候不能正常下载(网页未关闭),而且跳转到登录的页面,这种情况应该怎么用爬虫下载呢?