想用pycharm爬虫提取一个网页
用python做爬虫,网站http://fz.people.om.cn/skygb/sk/
结果是这样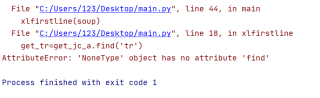
爬虫的话也爬不出来
import requests
from bs4 import BeautifulSoup #用bs4中的BeautifulSoup
import time
import random
def get_html(url):
try:
head = {'user-agent': 'Mozilla/5.0'}
html= requests.get(url,timeout=5)#请求获得网站(不要超时)
soup=BeautifulSoup(html.content,'html.parser')#创建一个BeautifulSoup对象
return soup
except:
print('error')#如果弄不出来,就报个错
def xlfirstline(soup):
get_line=[]
get_jc_a=soup.find('div',class_='jc_a')
get_tr=get_jc_a.find('tr')
tr=get_tr.find_all('th')
for each_th in tr:
th=each_th.get_text()
get_line.append(th)
return get_line
def prt_ret(get_result):
with open(r'D:\学python\国家社科基金项目数据库.txt','a') as f:
while get_result:
for i in range(20):
f.write(get_result.pop(0)+'t')
f.write('\n')
def get_content(soup):
get_result=[]
get_jc_a=soup.find('div',class_='jc_a')
tr=get_jc_a.find_all('td')
for each_td in tr:
td=each_td.get_text()
get_result.append(td)
return get_result
def main():
url='http://fz.people.com.cn/skygb/sk/index.php/Index/index?&p=1'
soup=get_html(url)
xlfirstline(soup)
get_line=xlfirstline(soup)
prt_ret(get_line)
for i in range(3):
wait_time=random.randint(3,10)
time.sleep(wait_time)
url = 'http://fz.people.com.cn/skygb/sk/index.php/index/index/' + str(i + 1)
soup = get_html(url)
get_result=get_content(soup)
prt_ret(get_result)
if __name__ == '__main__':
main()
对你有帮助的话,建议采纳。
get_tr=get_jc_a.find()这里的出现错误,你看看find方法是不是在你定义的get_jc_a里
空类型没有find方法,你的soup是空的,你可以试着输出下
没有请求头,被反爬了。
html= requests.get(url,headers = head, timeout=5)