如何统计表中一行值为1的列(字段),并将其列名组合输出?

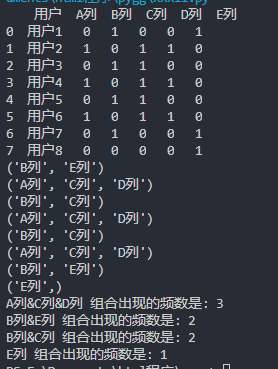
如上图,假设有这么一个类似的表,我想要知道表中字段值为1的字段,并将其列名组合输出。
目的是得知存在多少不同组合,并统计出不同组合出现的频数。
代码苦手是想用excel实现的,但实际上有上百个字段,数据量也不少,所以希望能用python解决。
急!!!希望能得到完整的代码解答!!!!
#-*- coding:utf-8 -*-
import pandas as pd
df = pd.read_excel('xxx.xlsx') ##默认读取sheet = 0的
print(df)
columns = df.columns.values.tolist()[1:]
dic = {}
for idx, row in df.iterrows():
tup = tuple(column for column in columns if row[column]==1)
print(tup)
dic[tup] = dic.get(tup,0) + 1
li = sorted(dic.items(),key=lambda x: x[1],reverse=True)
for ids, num in li:
print("&".join(ids),"组合出现的频数是:",num)

我的思路是第1列乘以2的0次方,第2列乘以2的1次方。。。,每行求和,和相同的行,必定是同一个组合,将和写成二进制,就是对应的组合结果。参考代码如下:
>>> import pandas as pd
>>> import numpy as np
>>> df = pd.read_excel(r'd:\demo.xlsx', sheet_name='Sheet1', index_col=0)
>>> df
微信 QQ 淘宝 微博 支付宝 美团 a b c d e f
用户1 0 1 0 0 0 0 0 1 0 0 0 0
用户2 1 0 0 1 0 0 0 0 0 0 1 0
用户3 0 0 0 0 0 1 0 0 0 1 0 0
用户4 0 0 1 0 0 0 0 0 0 0 0 0
用户5 0 0 0 0 0 0 0 0 1 0 0 0
用户6 0 0 0 0 1 0 0 0 0 0 0 1
>>> data = df.values
>>> for i in range(data.shape[1]):
data[:,i] *= pow(2,i)
>>> result = np.sum(data, axis=1).tolist()
>>> result
[130, 1033, 544, 4, 256, 2064]
>>> rank = list(set(result))
>>> for g, c in zip(rank, map(result.count, rank)):
print (bin(g)[2:][::-1], c)
0000010001 1
000000001 1
01000001 1
001 1
10010000001 1
000010000001 1
遍历excel表,得到列名组合的元组,将其做为字典的键名统计。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632