scrapy爬虫无法翻页
萌新刚刚开始接触爬虫,源网页是个小说网页,应该是没加反爬的机制的https://www.luoqiuzw.com/book/4841/74745706.html
测试了下,只爬单页的话完全没问题,问题点在于构建下一页地址和翻页条件都正确的情况下,无法执行翻页,有没有大佬帮忙看看是什么原因,下面就是主文件的代码
import scrapy
from luoqiu.items import LuoqiuItem
import re
class LuoqiuSpider(scrapy.Spider):
name = 'luoqiu'
allowed_domains = ['luoqiu.com']
start_urls = ['https://www.luoqiuzw.com/book/4841/74745706.html']
def parse(self, response):
item=LuoqiuItem()
item['title']=response.xpath('//*[@id="main"]/div/div/div[2]/h1/text()').extract_first() #获取标题
print(item['title'])#打印标题
item['zhengwen']=response.xpath('//*[@id="content"]/p[2]/text()').extract()#测试,只获取正文1行
print(item['zhengwen'])
next_url='https://www.luoqiuzw.com'+response.xpath('//*[@id="main"]/div/div/div[2]/div[1]/a[4]/@href').extract_first()#构建下一页
print(next_url) #https://www.luoqiuzw.com/book/4841/74745707.html
next_page=re.search(r'\d{8}',next_url).group() #提取下一页的页码7474707 str
print(next_page,type(next_page))#提取下一页的页码7474707 str
if int(next_page) <=74745720:#判断翻页,这边测试就翻几页
yield scrapy.Request (url=next_url ,callback=self.parse)
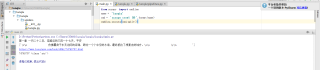
上面这个是执行结果
代码中的allow_domains有误,应该为:['louqiuzw.com']。原链接会出现连接丢失错误,与没有传递headers或网页响应慢有关。尝试测试其他网页,在start_urls列出测试网页地址列表。
class LuoqiuSpider(scrapy.Spider):
name = 'luoqiu'
allowed_domains = ['luoqiu.cc']
start_urls = [
f'https://www.luoqiu.cc/297/297526/{page}.html' for page in range(45813215, 45813220)]
rules = (
Rule(LinkExtractor(allow=r'297526/.*'),
callback='parse', follow=True),
)
def parse(self, response):
#code
你输出下一页的响应结果看看,应该下一页的响应结果出问题

已经执行到下一条了,但是响应的结果还是初始页面
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
非常感谢您使用有问必答服务,为了后续更快速的帮您解决问题,现诚邀您参与有问必答体验反馈。您的建议将会运用到我们的产品优化中,希望能得到您的支持与协助!
速戳参与调研>>>https://t.csdnimg.cn/Kf0y