spark集群启动报错了,大佬们帮忙看一下呗
spark集群启动报错了,大佬们帮忙看一下呗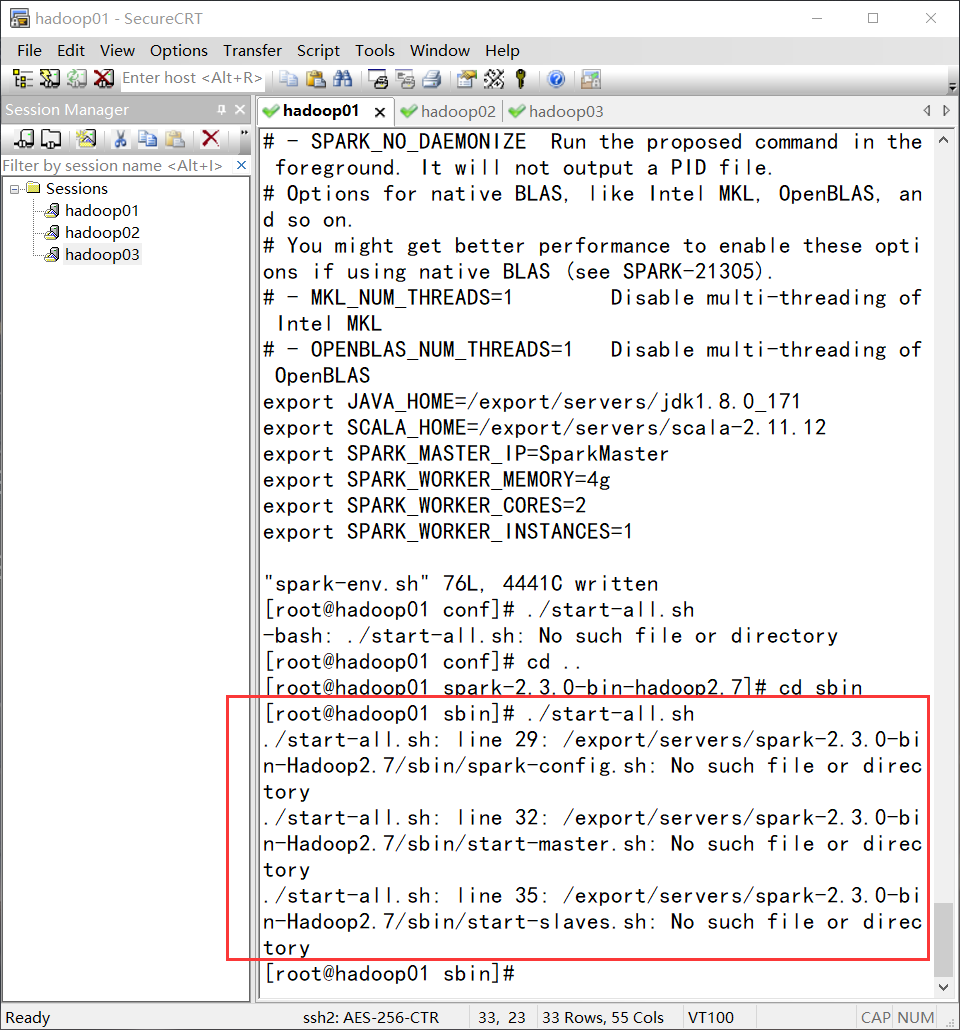 不知道你这个问题是否已经解决, 如果还没有解决的话:
不知道你这个问题是否已经解决, 如果还没有解决的话:
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
不知道你这个问题是否已经解决, 如果还没有解决的话:- 文章:记一次spark数据倾斜问题解决过程 中也许有你想要的答案,请看下吧
- 除此之外, 这篇博客: 大数据 - 大数据开发技术课程总结(未完)中的 2.4.3 启动spark集群 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
由于是用yarn模式运行,首先要启动yarn,启动yarn的方式是用hadoop下的start-all.sh.启动顺序是:hadoop的start-all.sh,spark的start-all.sh.
由于两个文件同名,所以必须区分是哪一个.区分的方式可以是,spark路径不配置环境变量,而是用全路径执行.Spark要在master节点上启动.
启动后,用jps查看,master节点:
NameNode
Jps
ResourceManager
Master
SecondaryNameNode
Slave节点:
DataNode
NodeManager
Worker
Jps
说明启动成功.
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^