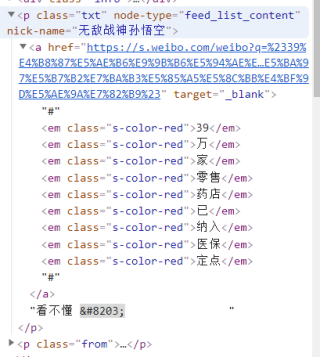
在提取微博热搜问题是如何提取p下面的所有文本啊(里面是a和em标签)
https://blog.csdn.net/baidu_39384178/article/details/112689254
正则表达式,通过判定</em>关键标签提取相关字段或屏蔽无效字符串
能具体写一下代码吗?感谢
a标签里的#号需要吗
text="<p>p标签里面的文本内容</p>"
re.match("<p class='txt' node-type='feed_list_content' nick-name='无敌战神孙悟空'>(.*)</p>", text).group(1)
可能有几个符号需要转义一下,这样提取之后再match一下a标签和em标签就好了