怎样拿到这个网页下的uri数据?
在上面网页里面,我需要拿到如下图里面的uri数据,求大神告知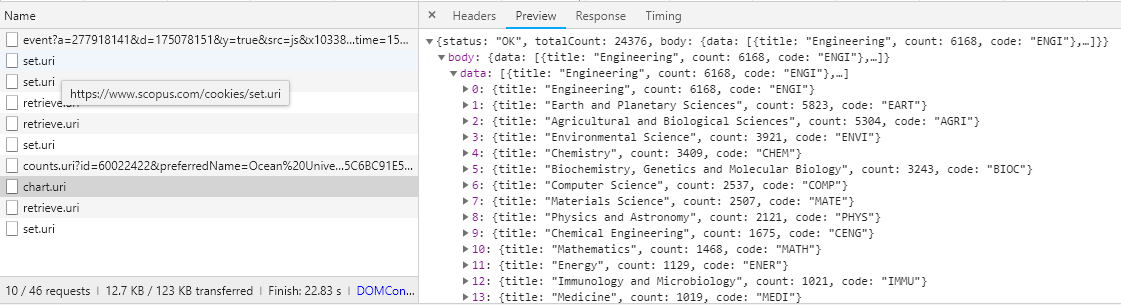
这个是动态加载的网站吧,用json返回的,我前几天刚爬了一个,肯定是get不到的,你得用post,然后得到的是preview后面那个菜单response里的东西,
那里应该包括你要的数据,找一下你需要的字段就行了,
在使用python3 request做接口测试的时候,想获取response的json中的某个值做断言时,发现request好像没有相关的方法
所以只好自己找写一个了。在我看来,json就是一个字典,只不过是字典里面嵌套着字典、列表,列表里面有嵌套着字典。
所以我们跟根据上面的思路来解决这个问题。首先josn就是一个字典,所以第一个判断就是它是不是字典,是的话就用dict.items()
输入key和values,然后再判断values类型,如果是list,那就把list每个值取出来,再做判断。如此自我调用,实现取值。
class getvales():
def getdict(dict1, values):
global values1,va #定义全局变量
values1 = values
for k, v in dict1.items(): #把字典的key和values变成数组
if k == values:
va = v
elif list is type(v): #判断类型是不是list
getvales.getlsit(v)
elif type(v) is dict:
getvales.getdict(v, values1)
else:
print(str(k) + ":----" + str(v))
return va
def getlsit(list1):
for i in list1:
if list is type(i):
getvales.getlsit(i)
elif dict is type(i):
getvales.getdict(i, values1)
else:
print(list1)
if name == "__main__":
dict1 = {'result': {'content': [
{'areaCode': '4XXXXXXX00', 'branchFee': 100.0, 'checkStatus': 'check_no', 'completionRate48': False,
'consignee': '刘先生', 'consigneeTel': '1XXXXXXXX64', 'countdown': 0, 'createDate': '2017-12-01 14:52:52',
'goods': '布皮艺沙发', 'id': 'WAQ2Wm2AjlEdwlRU', 'installFee': 40.0, 'items': 1, 'jingdong': False,
'jingdongConfirm': False, 'matchType': '人工匹配', 'matchingFailureReason': '此单xXXXXXX后再做安排',
'msfCheck': '未核销', 'orderSourceCode': '', 'orgName': '一智XXXXXXXX业部', 'packingNumber': 2, 'payArrive': 0.0,
'payCash': 0.0, 'payMonth': 120.0, 'payReturn': 0.0, 'payType': '月结', 'pickUpAddress': 'XXXXXXX库',
'pickUpTel': '13532120095', 'pickUpTime': '', 'readOnly': False, 'receiveAddress': '广东省广州市增城区XXXX',
'remark': '', 'replaceCharge': 0.0, 'serviceType': '配送到家并安装', 'shipper': 'XXXXX有限公司', 'taskStatus': '待分配',
'taskStatusShow': '待分配', 'taskType': '调度任务', 'tmail': False, 'trunkEndDate': '2017-12-01 15:27:06',
'volumes': 1.3, 'waybillId': '1zt18824149564', 'weights': 0.0, 'worker': 'XXX', 'workerTel': '13XXXXXXXX37'}],
'first': True, 'last': True, 'number': 0, 'numberOfElements': 1, 'size': 10, 'totalElements': 1,
'totalPages': 1}}
abc = getvales.getdict(dict1, "waybillId")
print(abc)
楼上的大佬,我想要爬取uri里面的数据,是获取的方法不懂,用requests.get获取不到
你要获得域名里的东西吗?看看这个http://ju.outofmemory.cn/entry/344949