在Java程序中如何匹配正则表达式所匹配的结果?
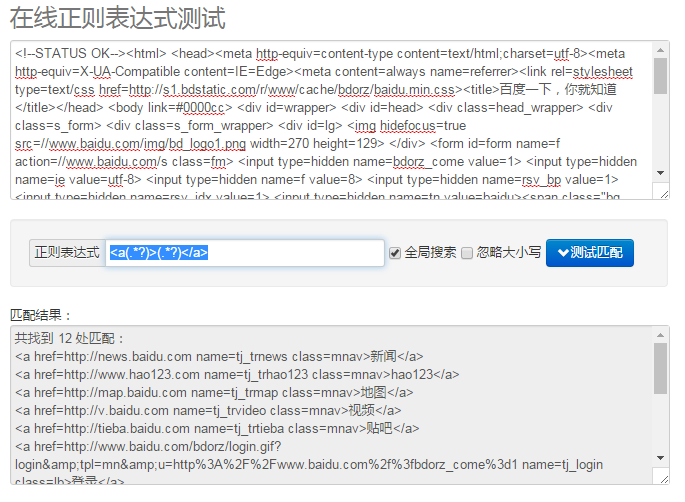
例如我写了一个正则,可以匹配百度上面所有的a标签
public static void main(String[] args)
{
String baiduHtml = getUrlString();
System.out.println(baiduHtml);
Pattern pattern = Pattern.compile("<a(.*?)>(.*?)</a>");
Matcher matcher = pattern.matcher(baiduHtml);
if (matcher.find()) {
System.out.println(matcher.group());
}
}
输出结果
<a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a>
对于这类xml格式,最好不用正则匹配,处理会很麻烦
可以用xml类库来解析
http://www.ibm.com/developerworks/cn/xml/dm-1208gub/
一般处理xml不会用正则,而是xpath
可以用matcher,参考
http://blog.csdn.net/debugingstudy/article/details/12720087
正则表达式分组命名捕获 (?(.*?))
http://blog.csdn.net/su1216/article/details/49407381
正则表达式分组命名捕获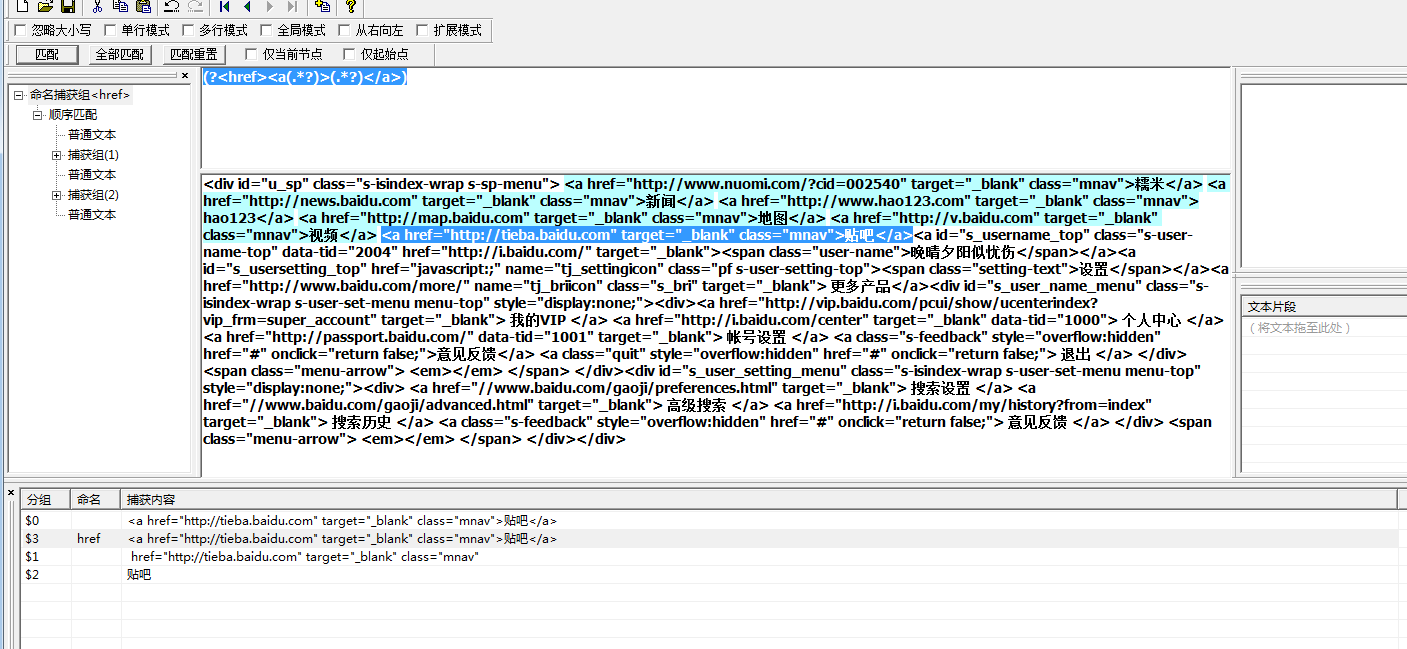
http://blog.csdn.net/su1216/article/details/49407381
String s = "2015-10-26";
Pattern p = Pattern.compile("(?\d{4})-(?\d{2})-(?\d{2})");
Matcher m = p.matcher(s);
if (m.find()) {
System.out.println("year: " + m.group("year")); //年
System.out.println("month: " + m.group("month")); //月
System.out.println("day: " + m.group("day")); //日
System.out.println("year: " + m.group(1)); //第一组
System.out.println("month: " + m.group(2)); //第二组
System.out.println("day: " + m.group(3)); //第三组
}