多维度统计表作业-用python进行编程
地区 月份 人员 补贴 工作量
山东 2020年2月 张三 10 1
上海 2020年2月 李四 20 3
江苏 2020年2月 王五 30 6
浙江 2020年2月 马六 13 9
山东 2020年3月 刘七 5 1
江苏 2020年3月 赵八 30 3
上海 2020年3月 钱九 20 5
江苏 2020年3月 孙十 12 7
要求: 1 统计每个月每个地区的补贴数字
2 统计每个月每个人的工作量
要求用python进行统计,不用pandas模块,尽量减少重复代码
data = {'地区':['山东','上海','江苏','浙江','山东','江苏','上海','江苏'],
'月份':['2020年2月','2020年2月','2020年2月','2020年2月','2020年3月','2020年3月','2020年3月','2020年3月'],
'人员':['张三','李四','王五','马六','刘七','王五','钱九','孙十'],
'补贴':[10,20,30,13,5,30,20,12],
'工作量':[1,3,6,9,1,3,5,7]
}
def sumInAtt(att,value,data=data):
res = {}
for i,d in enumerate(data['月份']):
if d in res:
# continue
if data[att][i] in res[d]:
# continue
res[d][data[att][i]] += data[value][i]
else:
res[d][data[att][i]] = data[value][i]
else:
res[d] = {data[att][i]:data[value][i]}
return res
#统计每个月每个地区的补贴数字
sumInAtt('地区','工作量')
# 1 统计每个月每个地区的补贴数字
sumInAtt('人员','补贴')
结果: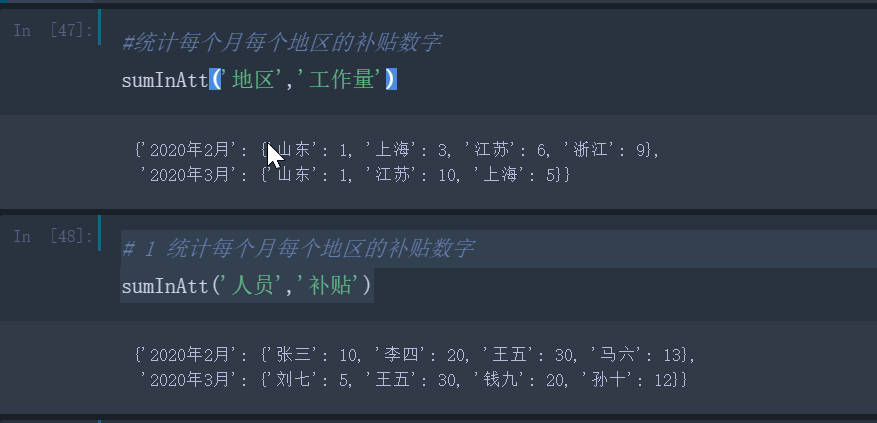
首先对数据按照地区排序,然后遍历一次就可以累加输出了。