python爬取动态网页时为什么动态网页的url的源码和网页源码不一样?
想用python爬虫爬burberry官网https://cn.burberry.com/mens-new-arrivals-new-in/
的最新上架衣服图片,但网页是动态加载的(有一个查看全部按钮)
点击查看更多后有一个XHR请求如图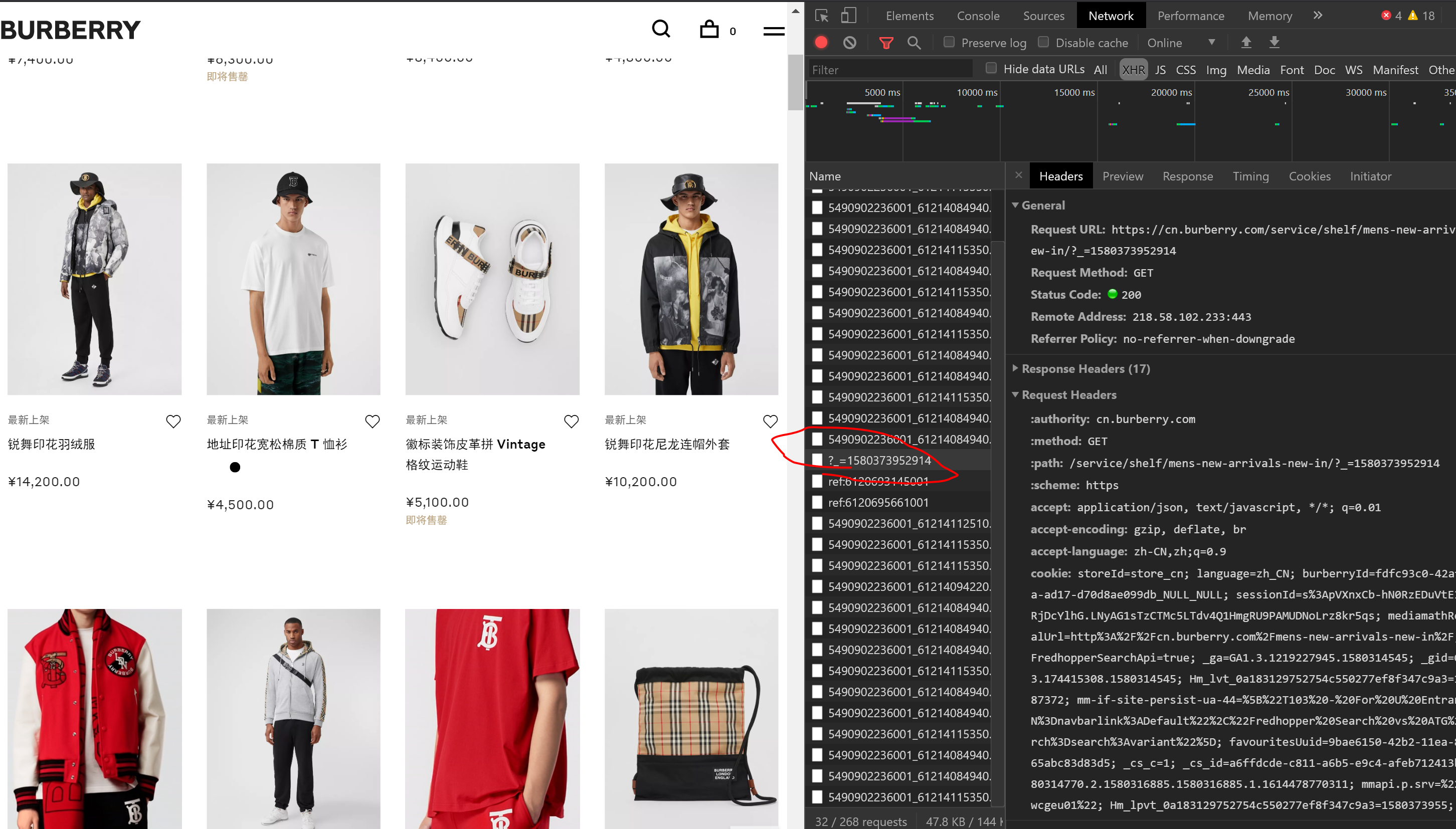
修改爬虫header后访问该请求的url,得到的html和在原网页上按f12显示的源码不相同,如图(图一为原网页点击加载全部后的源码,图二为访问url得到的源码)

为什么会不一样呢????而且不一样的话按照url得到的格式我就没法用美丽汤了,只能正则找图片链接,怎么样得到原网页点击加载全部后的源码呢???(小白刚学爬虫,希望大佬指教)
加载更多是通过ajax异步加载的
请求的是 Request URL: https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/?_=1580390113449
1580390113449应该是时间戳,没有特殊含义,表示1970-1-1到现在的毫秒数
包括如下附加的http header
x-content-type-options: nosniff
x-newrelic-app-data: PxQEVV9WDwQTVVhQAQMEU1MTGhE1AwE2QgNWEVlbQFtcCxYkSRFBBxdFXRJJJH1nH0sSB0VHXgUBHkVbBwoFQBxSFFIWCQQBAFEBVAhNHlNIFAVQVAIPVlYCVQcPA1NeRh1QUg4VBj8=
x-xss-protection: 1; mode=block
返回的json就是你要的。