一,布隆过滤器介绍
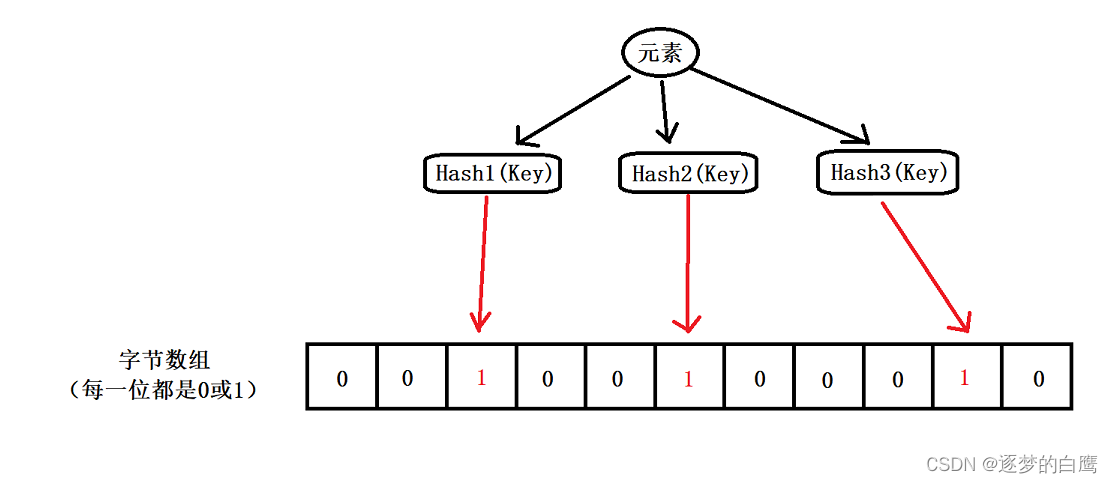
布隆过滤器(Bloom Filter)是一个很长的二进制向量(位图BitMap)和一系列随机映射函数(Hash函数)。它是一种数据结构,可以判断一个元素一定不在集合中或可能存在于集合中。
优点:相比于传统的list、set、map等数据结构,它更高效、占用空间更少。
缺点:存在误判率
二,布隆过滤器原理
布隆过滤器是一个字节向量,初始值全部为0

1. 原理
当一个元素被加入集合时,通过K个hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。
2. 检索元素
通过k个点位(Hash函数个数)的值进行判断。
- k个点位中有任一为0,被检元素一定不存在。
- k个点位都是1,被检元素可能存在。
三,布隆过滤器设计
布隆过滤器存在误判率,在查找元素值都返回1的时候,我们没法确定该元素就一定存在,不过我们可以通过一些参数的设置来降低误判率。
假设:
| M | 向量表的长度 |
| K | 哈希函数的个数 |
| N | 插入的元素个数 |
| P | 误判率 |
在实际应用中,我们一般是可以给定N、P,然后计算出M、K。
1. 向量表的长度 M 计算

2. 哈希函数个数 K 计算
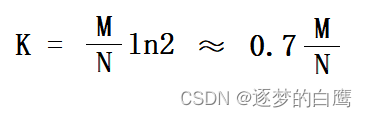
3. 哈希函数的选择
- 常见应用比较广的hash函数有MD5,常用于签名认证和加密等。比如我们传文件时习惯对原文件内容计算它的MD5,生成128bit的整数,通常我们说的32位MD5,是转换为16进制后的32个字符。
- MurmurHash相比较MD5,不太安全。但性能是MD5的几十倍。MurmurHash有多个版本,MurmurHash2,MurmurHash3。
我们可以选择MurmurHash2。
4. 注意
布隆过滤器不能删除元素,在布隆过滤器算法中会存在一个bit位被多个元素值覆盖的情况。
四,安装使用布隆过滤器
Redis 提供的 bitMap 可以实现布隆过滤器,但是需要自己设计映射函数和一些细节,这和我们自定义没啥区别。
Redis 官方提供的布隆过滤器到了 Redis 4.0 才正式登场。Redis 4.0 提供了插件功能,布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
安装 RedisBloom
在已安装 Redis 的前提下,安装 RedisBloom,有两种方式:
1. 直接编译进行安装:
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make #编译 会生成一个rebloom.so文件
redis-server --loadmodule /path/to/rebloom.so #运行redis时加载布隆过滤器模块
redis-cli # 启动连接容器中的 redis 客户端验证
2. 使用Docker进行安装:
docker pull redislabs/rebloom:latest # 拉取镜像
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest #运行容器
docker exec -it redis-redisbloom bash
redis-cli
使用布隆过滤器
布隆过滤器基本指令:
- bf.add 添加元素到布隆过滤器
- bf.exists 判断元素是否在布隆过滤器
- bf.madd 添加多个元素到布隆过滤器,bf.add 只能添加一个
- bf.mexists 判断多个元素是否在布隆过滤器

上面使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次 add 的时候自动创建。
Redis 还提供了自定义参数的布隆过滤器,bf.reserve 过滤器名 error_rate initial_size
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降
但是这个操作需要在 add 之前显式创建。如果对应的 key 已经存在,bf.reserve 会报错
127.0.0.1:6379> bf.reserve user 0.01 100
(error) ERR item exists
127.0.0.1:6379> bf.reserve topic 0.01 1000
OK
五,布隆过滤器部分源码
基于Redis位图(BitMap)实现的布隆过滤器的源码地址:
https://github.com/xqiangme/spring-boot-example/tree/master/spring-boot-redis-bloomFilter
向量表的长度 M 与 哈希函数个数 K 的计算
void CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk)
{
/**
* n - Number of items in the filter //要插入的元素个数
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p //误判率
* m - Number of bits in the filter //向量表的长度
* k - Number of hash functions //哈希函数的个数
*
* f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n)
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
// 计算指定假阳(误差)概率下需要的比特数(向量表长度)
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453); //向上舍入为最近的整数
m = (m - m % 64) + 64; // 8字节对齐
// 计算哈希函数个数
double double_k = (0.69314 * m / n);
k = round(double_k); // 返回四舍五入整数值
*pm = m;
*pk = k;
return;
}
六,布隆过滤器的应用
1. 黑名单校验
2. 快速去重
3. 爬虫URL校验
4. 解决Redis的缓存穿透问题(在Redis专栏会详细讲解)
七,布隆过滤器的优缺点
优点:
1. 占用内存少,插入和查询速度快,时间复杂度都为 O(K)。
2. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
缺点:
1. 存在误判率。
2. 无法删除元素。