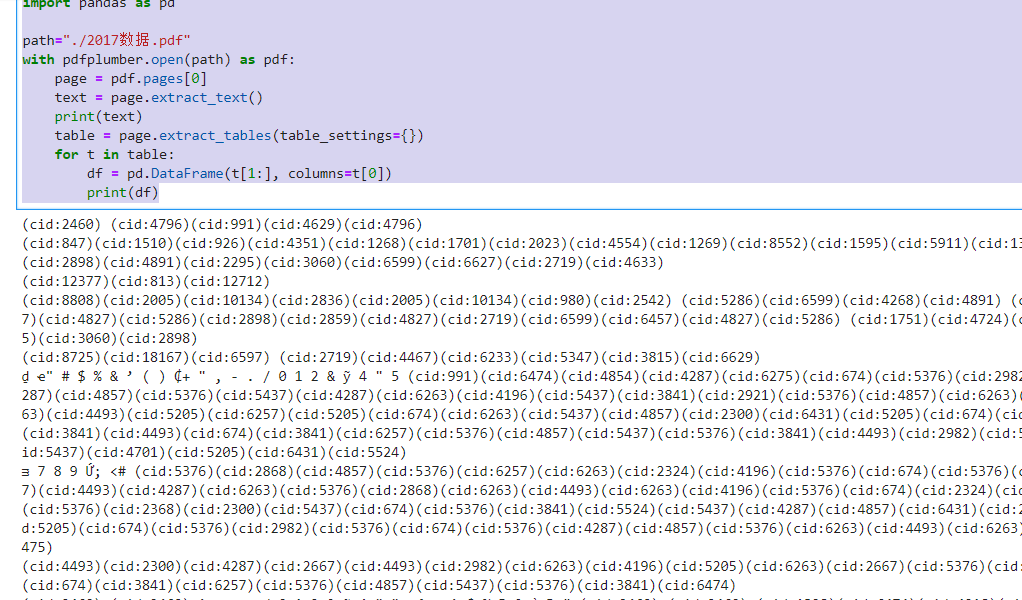
使用pdfplumber提取pdf表格内容时,得到的全是cid:xxxx,怎么解决?
import pdfplumber
import pandas as pd
path="./2017数据.pdf"
with pdfplumber.open(path) as pdf:
page = pdf.pages[0]
text = page.extract_text()
print(text)
table = page.extract_tables(table_settings={})
for t in table:
df = pd.DataFrame(t[1:], columns=t[0])
print(df)
建议你换一个思路,用pdf2txt或者类似的工具,转换成文本文件,然后再稍微调整转换成csv
最后再用pandas的readcsv去读取
chr(int(2460))