如何从整体去推算个体的数量
假如有100个筐里随机装了各种水果,目前只能知道每个筐里总体的数量以及各种水果的有无,请问有没有什么方法能预测出每种水果的数量,或者平均值?
你可以用k-means,相似的水果归为一类,聚类中心就是这类相似的水果的特征(包括数量和其他属性),在统计每个聚类的中心的数量信息,就能得到每种水果的数量或平均值。
引用 皆我百晓生 小程序回复内容作答:
要预测每种水果的数量或平均值,可以使用统计学的方法,例如抽样调查和推断统计。
抽样调查:从100个筐中随机选择一部分进行观察和计数。可以使用简单随机抽样或分层抽样等方法确保样本具有代表性。通过统计样本中每种水果的数量,可以推断出整体的每种水果的数量。例如,如果从样本中抽取的100个筐中共有20个苹果,那么可以推断整体的100个筐中大约有20个苹果。
推断统计:使用已知的总体信息和样本统计量,进行统计推断来估计每种水果的数量或平均值。例如,如果知道总体中每种水果的总数量,以及样本中每种水果的数量,可以使用比例估计来推断每种水果的数量。另一种方法是使用区间估计来估计每种水果数量的范围。
机器学习方法:可以使用机器学习算法来预测每种水果的数量。可以使用线性回归、决策树、随机森林等回归算法进行建模。首先,将筐的总体数量和各种水果的有无作为特征,将每种水果的实际数量作为目标变量进行训练。然后,使用已经训练好的模型来预测其他筐中每种水果的数量。
需要注意的是,以上方法都需要有足够的样本和特征信息才能进行有效的预测。如果样本数量有限或特征信息缺失,预测结果的准确性可能会有所限制。
该回答通过自己思路及引用到GPTᴼᴾᴱᴺᴬᴵ搜索,得到内容具体如下:
在给定每个筐中水果总数和水果种类的情况下,可以使用统计学方法来估计每种水果的数量或平均值。下面介绍两种常用的方法:
抽样估计:抽样估计是通过从总体中选择一部分样本进行观察和统计,然后根据样本数据对总体进行推断。你可以从每个筐中随机选择一些样本来统计包含的水果种类和数量。然后,基于样本数据,使用抽样估计方法(如无偏估计)来估计每种水果的数量或平均值。
区间估计:区间估计是通过对总体进行抽样并计算样本统计量的置信区间来估计总体参数。你可以从每个筐中随机选择一些样本,并计算每种水果的数量或平均值的置信区间。置信区间提供了一个范围,该范围内的真实参数值有一定的置信度。通过这种方法,你可以得到每种水果数量或平均值的一个范围估计。
无论使用抽样估计还是区间估计,样本的选择应该是随机的,并且样本应该足够大,以确保估计的准确性。此外,还应考虑总体的分布情况和可能的偏差来源。
需要注意的是,这些方法只是对总体水果数量或平均值的估计,并不能提供确切的数值。准确性和可靠性取决于样本的代表性和样本量的大小。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
对于这个问题,可以使用统计学中的抽样方法来估计每种水果的数量或者平均值。具体步骤如下:
首先,从这100个筐中随机抽取一部分筐(称为样本),确保样本是随机且代表性的。
对于每个样本筐,统计其中各种水果的数量。
根据样本筐中各种水果的数量,可以使用抽样分布理论来估计整体筐中每种水果的数量的概率分布或平均值。
通过对多次抽样并估计每种水果数量或平均值的过程,可以得到更准确的估计结果。
需要注意的是,这种方法是基于随机抽样和统计推断原理,结果的准确性还受到样本数量和抽样方法的影响。
对于这个问题,可以利用一些基本的统计和数据分析方法。首先,需要明确的是,如果只知道每个筐里总体的数量以及各种水果的有无,那么预测每种水果的数量或平均值是有挑战的,因为这个问题本质上是一个多元线性回归问题,需要知道每种水果的具体数量,才能进行有效的预测。
然而,如果假设每个筐内各种水果的数量是随机的,且每个筐内的水果总数是已知的,那么可以使用贝叶斯统计的方法对每种水果的数量或平均值进行预测。具体来说,可以将问题视为一个贝叶斯多项分布问题,其中每个筐内的水果总数是已知的,而每种水果的数量是未知的。
这样的问题可以使用一些基本的贝叶斯推断方法解决,例如MCMC (Markov Chain Monte Carlo)采样方法,这种方法可以从后验分布中抽样,得到每种水果数量的可能值。然而需要注意的是,这种方法只能提供预测结果的概率分布,而不能提供确切的数量或平均值。
此外,如果每个筐内水果的总数和种类都是已知的,那么可以使用多项式分布的期望和方差来估计每种水果的数量或平均值。具体来说,如果某个筐内有N个水果,其中有K种不同的水果,那么每种水果的期望数量是N/K,方差是N/K*(1-1/K)。
总的来说,对于这个问题,可以使用贝叶斯统计的方法和多项式分布的期望和方差来预测每种水果的数量或平均值。然而需要注意的是,由于这个问题的本质是一个多元线性回归问题,因此预测的结果只能是一个概率分布,而不是确切的数量或平均值。
【相关推荐】
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/179286
- 这篇博客也不错, 你可以看下【图像恢复与目标检测】揭示域效应:视觉恢复如何有助于水中场景中的目标检测
- 您还可以看一下 数智优佳学堂老师的智慧水务(水利)专题-如何设计水务(水利)管理解决方案?课程中的 版权声明小节, 巩固相关知识点
- 除此之外, 这篇博客: 规划问题的建模与编程(一)投资问题中的 模型二、固定盈利水平,极小化风险 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
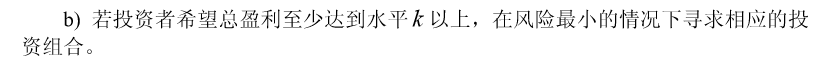
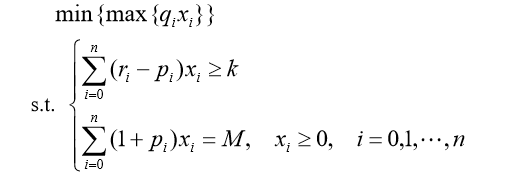
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
根据你的样本数据估算每种水果的平均数量。这可以通过简单的平均数估算来完成。例如,如果你有10个筐的样本数据,你可以计算每种水果在这10个筐中的平均数量,然后将这个平均值乘以100来估算所有100个筐中的总体数量。
用kmeans聚类。
结合GPT给出回答如下请题主参考
这个问题可以用概率统计中的抽样和估计方法来解决。假设你要估计苹果的数量,可以采取以下步骤:
随机抽取一定数量的筐,比如说10个。
统计这10个筐中苹果的数量总和,以及出现苹果的筐的数量。
假设这10个筐是从总体中随机抽取的,那么可以根据中心极限定理得出,这10个筐中苹果的数量总和的均值和方差分别等于总体中苹果的数量总和的均值和方差除以10。
根据上述均值和方差估计总体中苹果的数量总和的均值和方差,以及苹果的数量的均值和方差。
假设苹果的数量分布符合正态分布,可以利用均值和方差来估计每个筐中苹果的数量的概率分布。
下面是一个Python代码示例来实现上述步骤:
import random
import numpy as np
from scipy.stats import norm
# 假设总筐数为100,其中包含苹果、梨子和香蕉
total_baskets = 100
total_fruits = {'apple': 0, 'pear': 0, 'banana': 0}
# 随机选择10个筐进行抽样
sample_baskets = random.sample(range(total_baskets), k=10)
# 统计每种水果的数量总和和有水果的筐的数量
for basket in sample_baskets:
# 假设每个筐中的水果数目服从均值为10,方差为3的正态分布
apples = max(0, round(np.random.normal(10, 3)))
pears = max(0, round(np.random.normal(10, 3)))
bananas = max(0, round(np.random.normal(10, 3)))
total_fruits['apple'] += apples
total_fruits['pear'] += pears
total_fruits['banana'] += bananas
# 根据抽样结果估计总体中每种水果的数量
fruit_mean = {}
fruit_var = {}
for fruit in total_fruits:
mean = total_fruits[fruit] * total_baskets / 10
var = (total_fruits[fruit] / 10) ** 2 * total_baskets * (total_baskets - 10) / 9
fruit_mean[fruit] = mean
fruit_var[fruit] = var
# 根据均值和方差估计每个筐中每种水果的数量的概率分布
prob_dist = {}
for fruit in total_fruits:
prob_dist[fruit] = norm(loc=fruit_mean[fruit], scale=np.sqrt(fruit_var[fruit]))
# 输出结果
print('总体中每种水果的数量估计:', fruit_mean)
print('每个筐中苹果数量的概率分布:', prob_dist['apple'])
注意,这个方法的估计结果会受到抽样误差的影响,即估计得到的结果可能和真实值有一定偏差。为了减小抽样误差,可以增加抽样的数量或者重复抽样多次并取平均值。
在这种情况下,您可以尝试使用无监督学习中的聚类算法来预测每种水果的数量或平均值。以下是一种可能的方法:
- 数据准备:将每个筐中各种水果的有无转化为特征向量。可以使用独热编码(One-Hot Encoding)将每种水果的有无表示为二进制特征。
- 聚类算法:应用聚类算法(如K-Means、DBSCAN等)对筐进行聚类。聚类的目标是将具有相似特征(即各种水果的有无)的筐分组在一起。
- 聚类结果分析:根据聚类结果,可以得到每个聚类簇中的筐及其对应的特征向量。统计每个聚类簇中各种水果的数量或平均值来估计每种水果在该簇中的数量或平均值。
需要注意的是,聚类算法是一种无监督学习方法,无法直接预测每个筐中水果的具体数量。聚类结果提供了一种对水果数量或平均值的估计,但由于每个簇内的筐可能存在差异,这种估计可能存在一定的偏差。此外,对于稀疏数据,聚类算法的效果可能不如其他机器学习方法,因此在实际应用中需要根据数据的特点选择合适的方法。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import org.apache.commons.math3.ml.clustering.Cluster;
import org.apache.commons.math3.ml.clustering.Clusterable;
import org.apache.commons.math3.ml.clustering.KMeansPlusPlusClusterer;
public class FruitEstimation {
public static void main(String[] args) {
int numBaskets = 100; // 筐的数量
int numFruits = 5; // 水果种类数
List<Basket> baskets = generateBaskets(numBaskets, numFruits); // 生成筐并随机装入水果
Map<Integer, Integer> fruitEstimates = estimateFruitCounts(baskets, numFruits); // 估算每种水果的数量
// 打印估算结果
for (Map.Entry<Integer, Integer> entry : fruitEstimates.entrySet()) {
int fruitType = entry.getKey();
int fruitCount = entry.getValue();
System.out.println("Fruit type " + fruitType + ": Estimated count = " + fruitCount);
}
}
// 生成随机的筐并装入水果
private static List<Basket> generateBaskets(int numBaskets, int numFruits) {
List<Basket> baskets = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < numBaskets; i++) {
Map<Integer, Boolean> fruitPresence = new HashMap<>();
for (int j = 1; j <= numFruits; j++) {
boolean hasFruit = random.nextBoolean();
fruitPresence.put(j, hasFruit);
}
int totalFruitCount = random.nextInt(100); // 假设每个筐都有一个总体的水果数量
Basket basket = new Basket(fruitPresence, totalFruitCount);
baskets.add(basket);
}
return baskets;
}
// 通过K-Means算法估算每种水果的数量
private static Map<Integer, Integer> estimateFruitCounts(List<Basket> baskets, int numFruits) {
List<ClusterableBasket> dataPoints = new ArrayList<>();
// 将筐转化为聚类数据集的数据点
for (Basket basket : baskets) {
double[] features = new double[numFruits];
for (int i = 1; i <= numFruits; i++) {
boolean hasFruit = basket.getFruitPresence().get(i);
features[i - 1] = hasFruit ? 1 : 0;
}
ClusterableBasket dataPoint = new ClusterableBasket(features);
dataPoints.add(dataPoint);
}
// 创建K-Means聚类器并执行聚类
KMeansPlusPlusClusterer<ClusterableBasket> clusterer = new KMeansPlusPlusClusterer<>(numFruits,
100, new FruitDistanceMeasure());
List<Cluster<ClusterableBasket>> clusters = clusterer.cluster(dataPoints);
// 统计每个聚类簇中水果的数量
Map<Integer, Integer> fruitEstimates = new HashMap<>();
for (int i = 0; i < clusters.size(); i++) {
int fruitType = i + 1; // 水果种类从1开始编号
int clusterSize = clusters.get(i).getPoints().size();
fruitEstimates.put(fruitType, clusterSize);
}
return fruitEstimates;
}
// 表示一个筐
static class Basket {
private Map<Integer, Boolean> fruitPresence; // 水果的有无信息
private int totalFruitCount; // 水果总体的数量
public Basket(Map<Integer, Boolean> fruitPresence, int totalFruitCount) {
this.fruitPresence = fruitPresence;
this.totalFruitCount = totalFruitCount;
}
public Map<Integer, Boolean> getFruitPresence() {
return fruitPresence;
}
public int getTotalFruitCount() {
return totalFruitCount;
}
}
// 表示聚类算法的数据点
static class ClusterableBasket implements Clusterable {
private double[] features;
public ClusterableBasket(double[] features) {
this.features = features;
}
@Override
public double[] getPoint() {
return features;
}
}
// 自定义距离度量方式,根据水果的有无进行计算
static class FruitDistanceMeasure implements org.apache.commons.math3.ml.distance.DistanceMeasure {
@Override
public double compute(double[] a, double[] b) {
double distance = 0;
for (int i = 0; i < a.length; i++) {
distance += Math.abs(a[i] - b[i]);
}
return distance;
}
}
}
该回答通过自己思路及引用 [文心一言] 搜索,具体回答如下:
你的问题是关于如何预测每个筐中各种水果的数量或平均值,基于已知每个筐中水果的总数量和存在的种类。
这个问题可以通过使用机器学习或数据分析的方法来解决,但首先,你需要收集更多的数据。例如,你需要知道每个筐里各种水果的确切数量,以便能够训练你的模型。
假设你已经有了足够的数据,下面是一个简单的预测步骤:
数据清洗和预处理:首先,你需要确保你的数据是干净的,没有错误或遗漏。这可能涉及到检查每个筐中的水果总数是否与实际相符,以及确保每个筐中的水果种类都被正确记录。
特征选择:对于这个问题,可能的特征包括每个筐中的水果总数,各种水果的存在与否,以及可能的其他因素,如每个筐的大小等。
模型选择:根据你要预测的目标(各种水果的数量或平均值),你可能需要选择不同的模型。如果你要预测的是离散的值(例如,苹果的数量),你可能需要使用如决策树、随机森林或梯度提升机等模型。如果你要预测的是连续的值(例如,水果的平均重量),你可能需要使用线性回归、岭回归或LASSO等模型。
训练模型:使用你的训练数据和选择的模型进行训练。这通常涉及到调整模型的参数以优化性能。
验证和调整模型:使用一部分独立的数据(不参与训练的数据)来验证你的模型。这可以帮助你了解模型的性能如何,以及是否需要进一步调整。
预测:一旦你的模型经过训练和验证,你就可以用它来预测新的数据了。
以上步骤只是一个基本的框架,实际的过程可能会根据你的具体需求和数据而变化。希望这个答案能帮到你
如果只知道每个筐里水果的总体数量以及有哪些水果,没有其他任何信息,那么无法准确预测出每种水果的数量或平均值。因为每个筐里面可能含有不同数量、种类和比例的水果,而且不同筐之间也可能存在巨大的差异。
但是,如果我们可以随机从每个筐里抽出一些水果进行分析,那么我们就可以逐步了解每个筐里面各种水果的比例,从而推算出每种水果的数量或平均值。这个过程类似于统计学中的"抽样调查",通过抽样来估计总体的特征。不过要得到较为准确的结果,需要抽取足够多的样本和采用统计学上的一些技巧,否则可能会存在偏差。